

1. 서 론
반도체 8대 공정 중 금속 배선 공정(metallization)에는 텅스텐(tungsten, W) 또는 알루미늄(aluminum, Al)이 주 로 사용된다. 특히, 반도체 기술의 고도화, 3D 낸드플래 시메모리(NAND)의 고단화 과정에서 텅스텐 박막(CVDW, chemical vapor deposition of tungsten) 공정의 적 용이 확대되고 있다. 이에 따라, CVD-W 공정의 핵심 소재인 육불화텅스텐(tungsten hexafluoride, WF6)의 수요 가 증가하고 있다.1) WF6 제조 공정의 중간 산물인 텅 스텐 분말(tungsten powder)은 톤 단위로 생산되며, 생 산 과정에서 소량의 산화 분말(oxidation powder)이 혼 입될 경우 전량 폐기 처분하거나 재처리 공정을 거쳐야 한다. 즉, 산화 분말의 혼입은 WF6 제조 공정의 효율 을 저해하는 치명적인 요인이며, 경제적으로 큰 손실을 초래할 수 있다.
WF6 제조 공정에서 산화 분말의 혼입을 방지하기 위 하여, 기존에는 숙련된 작업자를 작업 현장에 24시간 배 치하여 관리하였다. 이러한 방식의 공정관리는 숙련된 작 업자의 경험과 판단에 의존하게 된다. 즉, 작업자의 검 출 속도와 정확도가 생산 수율, 제품의 품질에 큰 영향 을 미치게 되고 실제로 숙련된 작업자의 노동력을 활용 하여 24시간 일정 수준 이상의 품질을 유지하는 것 역 시 어려운 일이다. 이처럼 숙련된 작업자의 경험과 판 단에 의존한 기존 공정관리는 한계가 있다. 따라서 WF6 제조 공정의 생산성 향상을 위하여, 더 높은 정확도와 검출속도를 갖추고 일정한 수준 이상의 품질관리가 가 능한 자동화 검사 시스템의 도입이 필요한 상황이다.
본 논문에서는 합성곱 신경망(convolutional neural network, CNN)2) 기반의 YOLOv5 (you only look once v5)를 적용하여 WF6 제조 공정 중 산화 분말의 혼입을 실시간으로 검출하는 지능형 영상 감지 시스템을 제안 하였다. 제안하는 시스템의 구현 방안 및 성능 비교 분 석 결과를 제시하여, WF6 제조 공정의 효율화 방안에 대한 타당성을 입증하였다.
본 논문의 구성은 다음과 같다. 2장에서는 객체 탐지 알고리즘에 대한 관련 연구와 육불화텅스텐(WF6)의 제 조 공정을 기술한다. 3장에서는 제안하는 시스템의 구현 방안을 포함한 실험방법을 설명하고, 4장에서 실험 결과 를 정리한다. 5장에서는 결론 및 향후 연구계획을 제시 한다.
2. 이 론
2.1. 객체 탐지 알고리즘 관련 연구
최근 하드웨어 성능의 발전에 따라 그래픽스 처리 장 치(graphics processing unit, GPU)의 성능이 향상되었으 며, 영상 데이터의 처리 과정에 CNN이 적용되기 시작하 였다. 객체 탐지(object detection) 분야에 CNN을 적용한 대표적인 모델은 R-CNN (Region with CNN features) 이다. R-CNN3)은 2단계 검출기(two stage detector)로, 물체의 위치를 찾는 임무(region proposal)와 물체를 분류 하는 임무(region classification)를 단계적으로 구분하여 수 행한다. R-CNN은 입력 이미지를 받아서 selective search 알고리즘에 의해 생성된 region proposal 2,000개에 대 하여 합성곱 연산을 수행한다. 이러한 과정의 한계로 인 하여 계산 속도가 매우 느리다는 단점이 있다. Fast RCNN 4)은 R-CNN의 단점을 개선하기 위하여 제안되었고, ROI pooling 기법을 적용하여 CNN 연산 횟수를 줄이고 계산 속도를 증가시켰다. Faster R-CNN5)은 합성곱 특징맵 (convolution feature map)으로부터 region proposal을 직 접 생성할 수 있는 RPN (region proposal network)을 제 안하여, region proposal 과정에서 발생할 수 있는 병목 현상(bottleneck)을 개선하였다. R-CNN 계열의 알고리즘 은 개선과정에서 계산속도를 향상시켰지만, 실시간 객체 탐지(real-time object detection) 측면에서 한계점을 드러 냈다.
이러한 문제점을 해결하기 위한 대안으로 제시된 것이 YOLO(you only look once)다. YOLO6)는 1단계 검출 기(one stage detector)로서, 객체 검출의 개별 요소(객 체 탐지, 객체 분류)를 단일 신경망으로 통합한 모델이 다. YOLO는 많은 양의 이미지에 대하여 객체 탐지와 분류를 동시에 처리함으로써, 실시간 객체 탐지를 가능 하게 한다. YOLO는 이러한 설계적 특성으로 기존의 객 체 탐지 알고리즘보다 FPS (frame per second)가 우수 하며, mAP (mean average precision) 측면에서는 유사 한 수준의 성능을 보여준다.
YOLO는 이미지 내에 어떤 물체가 존재하고 어느 위 치에 있는지를 나타내기 위하여, 이미지 픽셀(pixel)로 부 터 경계 박스(bounding box)의 좌표(coordinates), 클래스 확률(class probability)을 구하기까지의 일련의 절차를 단 일 회귀 문제(single regression problem)로 재구성한다. YOLO의 단계별 과정은 아래와 같고, 이를 도식화한 것 이 Fig. 1이다.
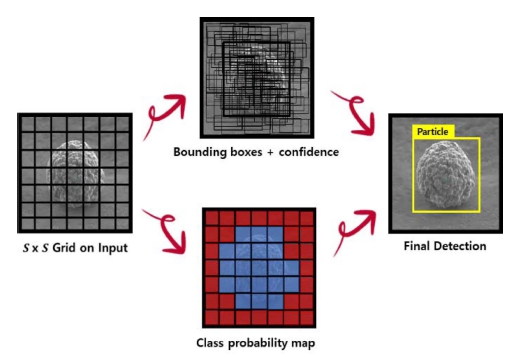
1) 입력 이미지를 S × S g r id c ell로 분할한다.
2) 각각의 g r id c ell은 객체 위치의 B개의 경계 박스와 각 경계 박스에 대한 확률점수(confidence score)를 예측 한다. 확률점수(confidence score)는 해당 box에 물체가 있 는지 없는지에 대한 점수와 예측 박스(prediction box)와 정답 박스(ground truth box)의 IoU (Intersection over Union) 값의 곱을 의미하며, 식 (1)과 같이 표현된다.
3) 각 grid cell은 conditional class probability (C)를 계산하며, Pr(Classi|Object)로 표현한다.
4) 각 경계 박스는 중심점인 (x, y)와 width와 height 값 (w, h), 확률점수(confidence score, C)를 포함한 5가 지 (x, y, w, h, C)로 구성된다.
5) 전체 이미지 격자로 나뉘게 되고, S × S × (B × 5 + C)개의 값을 예측한다.
6) YOLO 손실 함수는 식 (2)와 같다.
S: grid cell 크기
B: S 셀의 경계 박스
x, y: 경계 박스의 중심점
w, h: 경계 박스 width, height (이미지 전체의 width, height : 1)
C: Confidence Class Probability
YOLOv27)는 9,000개의 서로 다른 이미지를 탐지 및 분 류한다. 19개의 계층으로 이루어진 Darknet–19를 특징 추 출기(feature extractor)로 사용하며, YOLOv1의 dropout 을 배치 정규화(batch normalization)로 대체하면서 과적 합(overfitting)을 예방하였다. 그리고 초기 학습 안정화를 위해 앵커 박스(anchor box)를 도입하였으며, 경계 박스 의 예측을 완전 연결 계층(fully connected layer) 대신 앵커 박스에서 수행하여 예측 성능을 향상시켰다.
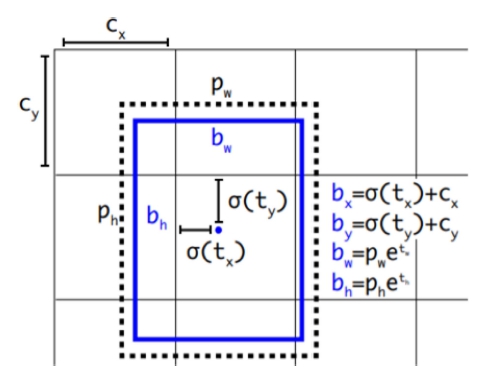
YOLOv38)는 Darknet-53을 특징 추출기(feature extractor) 로 사용하였고, 성능 향상을 위해 로지스틱 회귀(logistic regression)를 적용하여 각각의 경계 박스마다 객체의 유 무를 산출하는 객관성 점수(objectness score)를 예측하였 다. Fig. 2와 같이 앵커 박스와 ground truth box 사이 의 IOU가 가장 높은 박스를 예측 결과로 선택하고, 이 외의 박스들은 무시한다.
YOLOv49)는 빠른 실행 속도와 병렬 연산 최적화를 목표로 최신 기법을 조합하여 제안하였다. YOLOv4의 Backbone은 CSP-Darknet53, Neck은 SPP10) (Spatial Pyramid Pooling), PA-Net11) (Path Aggregation Network), Head는 YOLOv3를 적용하였다. 특히, Fig. 3과 같이 데이 터 증강 기법으로 전혀 다른 4개의 이미지를 하나의 이미 지로 결합하는 모자이크 증강 기법(mosaic augmentation)12) 을 적용하였다.

YOLOv513)는 Backbone-Neck-Head의 아키텍처로 구 성되어 있다. Backbone은 입력된 이미지에서 특징을 추 출하기 위하여 CSPDarknet14)을 사용하고, 총 4가지 모 델 ‘s, m, l, x’이 있으며 각각 small, medium, large, x-large를 뜻한다. 계산이 가장 빠르지만, 정확도가 상 대적으로 낮은 ‘s’부터 계산은 느리지만, 정확도가 가장 높은 ‘x'로 구분할 수 있다. 각각의 모델은 2가지 변수 (depth_multiple, width_multiple)에 의하여 결정된다. depth_multiple 값을 크게 할수록 BottleneckCSP14)의 반복 횟수가 증가하게 되면서 더 깊은 모델이 되고, width_multiple 값을 크게 할수록 Layer의 합성곱 필 터 수가 증가하게 된다. YOLOv5 Backbone 관련 변수 설정은 Table 1과 같다. Neck은 PA-Net을 사용하며, feature pyramids network을 생성한다. Head는 YOLO v3 및 v4와 동일하며, 추출된 특징맵을 바탕으로 물체 의 위치를 찾는 역할을 담당한다. PA-Net을 이용해 얻 은 서로 다른 크기의 특징 맵에서 각각 3개의 앵커 박 스를 이용해 객체를 탐지한다.

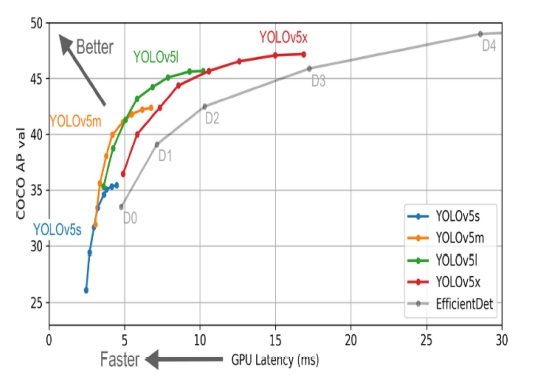
COCO dataset15)을 활용하여 YOLOv5 모델별 성능을 비교하면 Fig. 4와 같다. YOLOv5 모든 모델은 속도와 정확도 측면에서 EfficientDet16)보다 우수한 성능을 나타 냈다. 그리고 YOLOv5 모델의 layer 개수가 증가할수록 속도는 느려지지만, 정확도가 향상됨을 확인할 수 있다.
2.2. 육불화텅스텐(WF6) 제조 공정
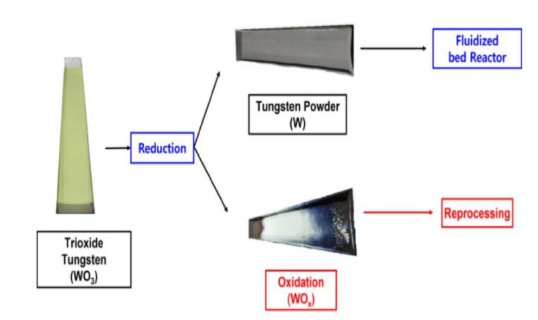
육불화텅스텐(tungsten hexafluoride, WF6)의 제조 공 정은 크게 6단계로 구성되며, 이를 도식화하면 Fig. 5 와 같다.
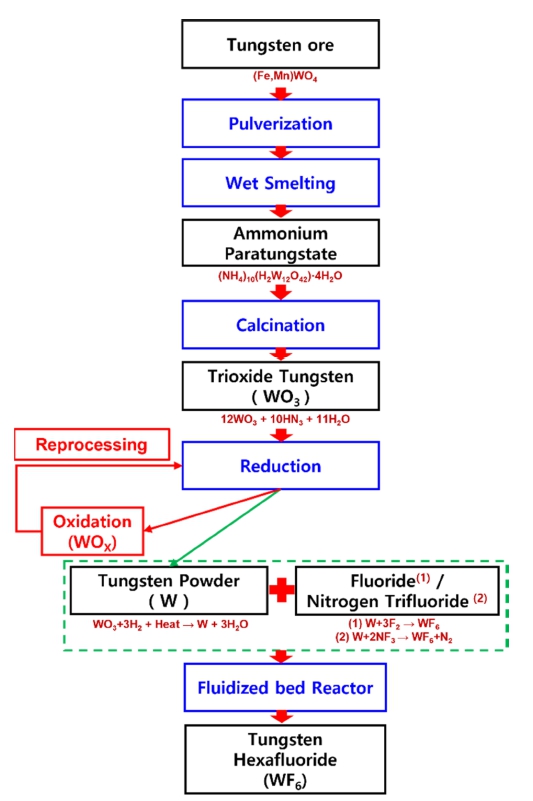
광물 형태의 텅스텐(tungsten ore)인 철망간중석[(Fe, Mn)WO4]을 분쇄(pulverization)하고, 이온 교환, 용매 추 출, 농축 및 결정화 등의 습식제련(wet smelting)공정을 거쳐서 파라텅스텐산 암모늄(ammonium paratungstate, APT)을 생성한다. APT를 약 500 °C에서 식 (3)과 같이 하 소(calcination)하여 삼산화텅스텐(trioxide tungsten, WO3)을 제조한다.
WO3는 약 500 ~ 1,300 °C 조건에서 식 (4)와 같이 수소(H2)와 환원 반응(reduction)을 통하여 텅스텐 분말 (tungsten powder, W)을 제조한다.17)
이 과정에서 식 (5)와 같이 산화 반응(oxidation reaction) 이 발생하는 경우, oxide가 포함된 텅스텐 분말(impure tungsten powder, WOx) 형태의 결함이 발생하게 되며, 이를 본 논문에서는 oxidation이라고 한다.
WF6 제조 공정에서 발생한 oxidation은 작업자가 결 함으로 분류하여, 환원(reduction) 공정을 다시 거치도록 재처리(reprocessing)한다. 정상으로 분류된 텅스텐 분말 (tungsten powder, W)은 불소(fluoride, F2) 또는 삼불화 질소(nitrogen trifluoride, NF3)와 함께 유동성 반응기 (fluidized bed reactor)에서 각각 식 (6), (7)과 같이 접 촉반응을 거쳐 육불화텅스텐(tungsten hexafluoride, WF6) 으로 제조된다.18)
3. 실험 방법
WF6 제조 공정의 중간 산물인 WO3가 실제 작업 환 경에서 환원 공정을 거치면서 생성되는 텅스텐 분말 (tungsten powder, W)과 oxidation을 나타내면 Fig. 6과 같다. 각각의 산물은 육안으로 구분이 가능하며, 영상 데 이터 분석을 통한 검출 시스템의 자동화가 가능할 것으 로 판단하였다.
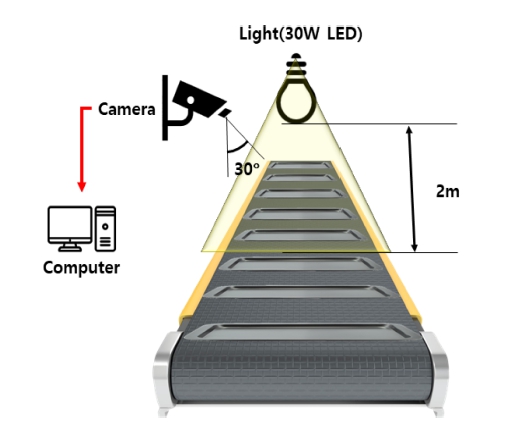
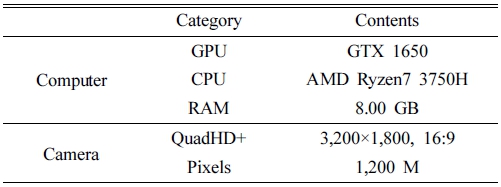
본 논문에서는 환원 반응 공정 후 생성된 텅스텐 분 말을 담은 트레이(tray)가 컨베이어벨트를 통해 이동하는 과정에서, 영상 데이터를 실시간으로 입력받아 oxidation 을 검출하는 지능형 영상 감지 시스템을 구현하고자 한 다. 30 W LED 조명은 컨베이어벨트로부터 2 m 높이에 설치되어 있으며, 카메라는 컨베이어벨트를 30°의 각도 에서 촬영한다. 제안하는 시스템의 개념도는 Fig. 7과 같 고, 하드웨어 적용 사양은 Table 2와 같다.
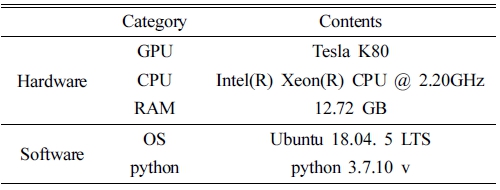
제안하는 시스템은 Google Colaboratory 활용하여 학 습을 진행하였고, 적용 환경은 Table 3과 같다.
3,024×3,024 크기의 영상 데이터를 1,248개 획득한 후, 정상으로 판단되는 텅스텐 분말(W) 트레이와 결함 으로 판단되는 oxidation (WOx) 트레이로 분류하였다. 이 렇게 사전 분류된 1,248개의 영상 데이터를 8:2의 비율 로 나누어, 998개의 영상 데이터를 학습 과정, 250개의 영상 데이터를 테스트 과정에 사용하였다. 그리고 실제 WF6 제조 공정 라인에서 수집한 영상 데이터에 대하 여 모자이크 증강 기법을 적용하였고, 그 결과는 Fig. 8과 같다. 모자이크 증강 기법을 통하여 Batch 수가 증 가하는 효과와 신경망 학습 안정성을 향상시켰다. 또 한, 영상 데이터를 c r op된 상태에서 학습함으로써 작은 객체에 대한 인식률도 함께 향상시켰다.
객체 검출 알고리즘에서 주로 사용되는 분류성능 평가 지표는 정밀도(precision)와 재현율(recall)이며, 각각의 정 의는 다음과 같다.
Precision은 식 (8)과 같이 모델이 ‘True’라고 판단한 것 중에서 실제 ‘True’인 것의 비율을 의미한다.
Recall은 식 (9)와 같이 실제로 ‘True’라고 판단한 것 중에서 실제 ‘ Tr ue’라고 예측한 비율을 의미한다.
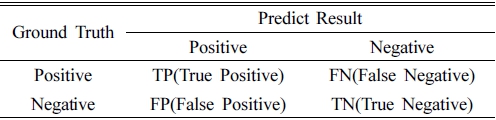
Precision과 Recall을 산출할 때, 활용되는 오차 행렬을 정리하면 Table 4와 같다.
4. 결과 및 고찰
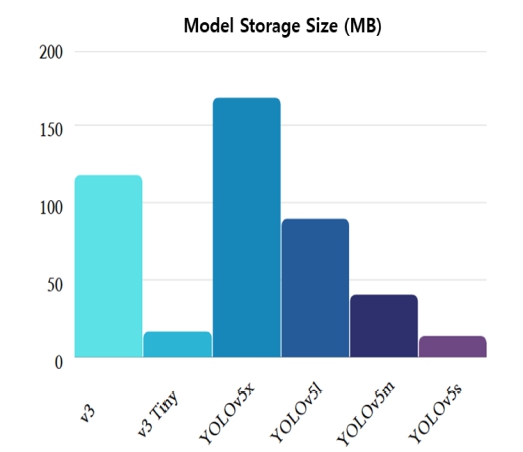
준비된 데이터셋을 기반으로 이미지 크기는 416 × 416, batch size 16, epochs 100의 동일 조건에서 YOLOv3, YOLOv3 Tiny, YOLOv5의 4가지 모델(v5s, v5m, v5l, v5x)을 활용하여 학습하였다. 각각의 모델에 대하여 precision, recall, mAP (mean average precision), FPS (frame per second)를 계산하여 Table 5에 정리하였고, 각 모델의 구현 과정에 사용되는 모델의 용량은 Fig. 9 와 같다.
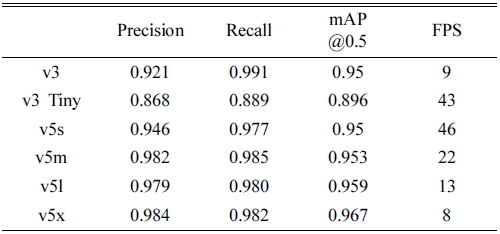
각 모델에 대한 실험 결과를 살펴보면, YOLOv5 계 열 모델이 YOLOv3보다 속도 및 정확도 측면에서 우수 함을 확인하였다. 그리고 YOLOv5 모델의 구현 과정에 서 활용된 스토리지 용량을 고려하였을 때, 지능형 영 상 감지 시스템에서 YOLOv5s의 적용이 타당한 것으로 판단하였다. 이러한 검토 결과를 바탕으로 실제 공정 영 상 데이터에 대하여 YOLOv5s를 적용한 결과는 Fig. 10 과 같다.

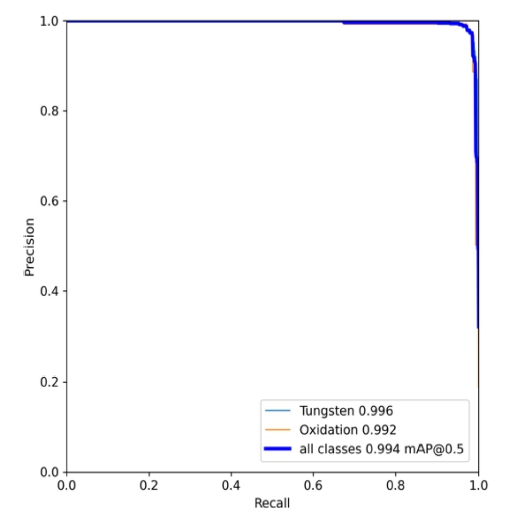
제안하는 시스템을 활용하여 텅스텐 분말(W)과 oxidation을 검출한 결과를 Fig. 11과 같이 Precision-Recall 곡선과 Table 6과 같이 tungsten powder 99.6%, oxidation 99.2 %, all classes 99.4 %의 높은 정확도와 FPS 46의 빠른 검출 속도를 확인하였다.


5. 결 론
본 논문에서는 WF6의 제조 공정에서 발생하는 oxidation 결함을 실시간으로 검출하는 지능형 영상 감지 시 스템을 제안하였고, YOLOv5를 적용하여 구현되었다.
제안하는 시스템이 생산 현장에 적용되면, 안정적인 품 질 관리와 효율적인 공정 관리에 기여할 것으로 기대된 다. WF6 제조 공정에서 수집한 영상 데이터를 기반으로 데이터셋을 구축한 다음, YOLOv3 계열(v3, v3 Tiny), YOLOv5 계열(v5s, v5m, v5l, v5x)의 알고리즘을 활용 하여 학습 및 성능 평가를 수행하였다. 총 6개 모델에 대하여 성능을 비교 평가한 결과, YOLOv5 계열 모델 이 YOLOv3 계열보다 속도 및 정확도 측면에서 우수함 을 확인하였다. 그리고 YOLOv5 모델의 구현 과정에서 활용된 스토리지 용량을 고려하였을 때, 지능형 영상 감 지 시스템에서 YOLOv5s의 적용이 타당한 것으로 판단 하였다. YOLOv5s로 구현된 시스템을 실제 공정 영상에 적용하여 텅스텐 분말 99.6 %, oxidation 99.2 %, all classes 99.4 %의 높은 정확도와 FPS 40의 빠른 검출 속도를 확인하였다.
제안하는 시스템에서 텅스텐 분말(정상 판단)이 검출되 면 후속 공정을 진행하고, oxidation(결함 판단)이 검출 되면 후속 공정 대신 reprocessing 공정을 자동으로 진 행시키는 스마트 제어 시스템에 대한 후속 연구를 진행 할 예정이다.
