

1. 서 론
영구자석 소재는 전기 자동차의 성장과 함께 다양한 모빌리티 기술이 발전하면서 필수적인 소재로서 오랫동안 연구되어져 왔다. 최근에는 전략소재로서의 국제적 환경변화로 인해서 희토류기반의 영구자석에 관심이 많아지고 있으며, 희토류 절감형 영구자석 소재 개발은 중요한 연구 분야중의 하나이다.1) 전기자동차에 사용되는 모터는 기존의 사용환경보다 더욱 높은 열적 안정성이 요구된다.2) 대표적인 영구자석 소재인 NdFeB보다 SmCo 합금 소재는 열적안정성이 높다고 알려져 있기 때문에 나노결정립 소재개발과, 다양한 원소 첨가를 통한 성능향상이 기대되면서 오랫동안 연구가 되고 있다.2,3,4) 또한 높은 자기 이방성과 열에 대한 보자력 감소 경향이 낮다고 알려져 있기 때문에 고에너지밀도의 영구자석 소재 개발과 관련되어서도 중요한 소재로 알려진 대표적으로 상용화된 영구자석 소재이기도 하다. SmCo 합금 영구자석은 복잡한 결정구조와 상호작용으로 인해서 최적의 소재 설계가 도전적인 부분이 있다.4,5) 또한 SmCo5, Sm2Co17 두 상이 함께 존재하면서 다양한 원소 첨가에 의한 나노결정립 특성의 조절을 통한 소재 최적화 연구가 활발히 진행되었다.6,7) 하지만 고전적인 trial-and-error 기반의 실험을 통한 최적화는 시간이 오래 걸릴 뿐 아니라, 실험과정에서 다양한 손실이 발생한다. 최근 데이터기반 소재 설계를 위한 기계학습 모델이 다양한 금속 소재에 적용되었다.4) 대표적으로 고엔트로피 합금, 연자성소재, 비정질 소재, 영구자석 소재등이 활발히 적용되고 있다. 그 중에서 SmCo 소재 개발을 위한 최근 연구에서 선형회귀 모델을 통한 새로운 조성 개발을 통해서 기계학습 모델의 잠재적 가능성이 보고되면서 열적 안정성과 높은 에너지밀도를 가지는 SmCo 합금기반의 영구자석 소재 개발에 관심이 높아지고 있다.4) 본 연구에서는 위에서 언급한 연구에서 보고된 SmCo 합금의 영구자석 소재 데이터를 사용하되,4) 조성기반의 특성인자만을 사용하여 기계학습 모델을 이용한 회귀 예측 성능을 확인하였다. 소재 데이터의 특성상 전체 데이터 숫자가 적기 때문에 본 연구에서는 인공신경망보다는 고전적 기계학습 모델을 사용하여 성능을 평가하였다. 자성 소재의 중요한 특징가운데 포화자화값과 보자력이 있는데, 보자력은 공정 과정에 크게 영향을 받기 때문에 소재 원소에 크게 의존하는 포화자화값을 예측하는데 중점을 두었다. 기계학습 모델가운데, 랜덤 포레스트(Random Forest, RF), 앙상블 부스팅 기법(XGboost, XGB), 서포트 벡터 머신(Support Vector Machine, SVR) 회귀 예측 모델을 통해서 예측 성능을 비교하였다. 최종적으로 유전알고리즘을 통해서 가장 우수한 성능을 보이는 RF 모델을 기반으로 주요한 특성인자를 탐색하여 기계학습 모델 최적화를 이루었다.
2. 실험 방법
Fig. 1은 본 연구에서 사용한 데이터의 특징을 분석하여 나타낸 것이다. Fig. 1(a)는 SmCo 영구자석 소재 데이터의 포화자화값의 분포를 히스토그램으로 나타낸 것이다. Fig. 1(b)는 소재 데이터에서 Co 함량에 따른 포화자화값의 변화를 보여준다. 전이금속 Co 함량이 높을수록 포화자화값이 증가하는 경향이 있음을 알 수 있다. 하지만 일반적으로 Sm 함량이 적을수록 자기이방성이 낮아지기 때문에 보자력이 감소하여 고에너지밀도 특성이 감소하게 된다. 또한 SmCo는 Sm 첨가로 인해서 열적 안정성이 NdFeB보다 강하다. 그러므로 Co와 Sm의 적절한 함량 조절이 열적 안정성과 고에너지 밀도 영구자석 소재 설계의 중요한 관건이 된다. Fig. 1(c)는 사용된 소재 데이터의 Co/Sm 비율에 따른 포화자화값의 변화를 보여준다. Co/Sm 비율에 따라서 선형적으로 포화자화값이 증가하는 것을 볼 수 있다. 이를 통해서 Fig. 1(b)의 단순히 Co 함량에 따른 변화보다는 Co/Sm 비율이 포화자화값 영향을 더욱 잘 표현한다고 할 수 있다. Fig. 1(d)는 기계학습에서 사용된 학습데이터와 테스트 데이터의 분포를 보여준다. 학습데이터와 테스트 데이터는 8:2로 분할하였으며, 학습데이터로 기계학습 모델을 학습한 후에, 테스트 데이터로 모델을 검증하여 성능지표를 비교하였다. 성능지표는 아래 식 (1), (2)에서 보여주는 것처럼 회귀모델에서 주로 사용되는 R2 score와 Root-mean-squared-error (RMSE)를 사용하였다.
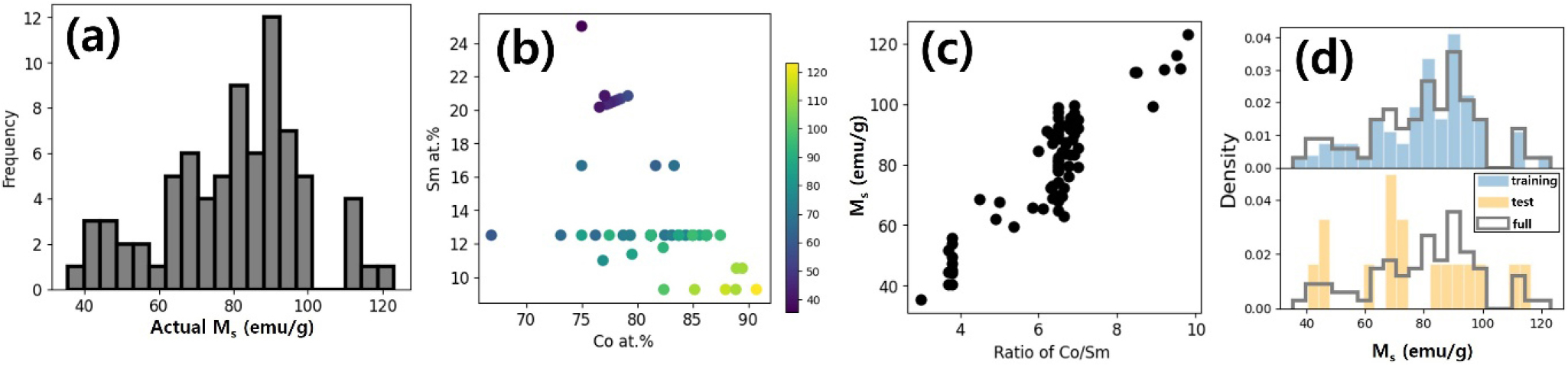
Fig. 1.
(a) Distribution of saturation magnetization values in the material dataset. (b) Relationship between saturation magnetization and the atomic ratios of Co and Sm in the dataset. (c) Distribution of saturation magnetization as a function of the Co/Sm ratio. (d) Histogram showing the distribution of training and test data used in the machine learning model.
위 식에서 는 학습과 테스트에 사용한 소재 데이터의 실제값이고, 는 학습된 모델을 통해서 얻은 예측값에 해당한다. N은 전체 데이터 개수를 의미한다.
Fig. 2는 본 연구에서 최적의 기계학습 모델을 얻기 위해서 사용된 전략적 개략도를 보여준다. 기계학습에 사용되는 소재데이터의 특성인자는 조성기반의 특성인자를 사용하였다. 앞선 연구에서 사용된 방법과 동일하게, 파이썬 모듈 Matminer와 Pymatgen을 이용하여 각 소재마다 특성인자 125개를 추출하였다.8,9) 앞서 데이터 분석에서 확인하였듯이 Co/Sm 비율을 특성인자로 추가하여 데이터 학습에 사용하였다. 많은 특성인자는 과대적합을 유발할 수 있기 때문에, 주요 특성인자를 찾고 그에 맞는 적절한 기계학습 모델을 탐색하기 위해서 랜덤 포레스트(RF), 앙상블 부스팅 기법(XGB), 서포트 벡터 머신(SVR)을 사용하여 예측 성능을 상호 비교하였다. 3가지 모델은 Table 1에서 보여주는 것처럼 하이퍼-파라미터 튜닝을 통해서 최적의 모델을 확인하였다. 하이퍼 파라미터 튜닝시에는 grid-search 방법과 교차검증을 통해서 최적화되었다. 이 가운데 RF가 가장 우수한 예측 성능을 보였으며, RF의 주요 특성인자를 순열 기반 중요도 탐색법(permutation feature importance, PFI)을 이용하여 예측에 미치는 효과가 큰 특성인자를 찾아 20개의 주요 특성인자를 확인하였다. 마지막으로 유전알고리즘 최적화 기법을 이용하여, 9개의 주요 특성인자를 찾았으며, 이를 통해서 최고 성능을 보이는 RF 모델을 얻을 수 있었다.

Table 1.
Hyperparameters Used and Optimized for the Three Machine Learning Models.
3. 결과 및 고찰
Fig. 3은 기계학습 모델에서 사용한 특성인자 126개를 기반으로 하여 하이퍼 파라미터 튜닝을 통해서 최적화된 3개 모델의 회귀 예측 성능을 보여준다. 학습 데이터와 테스트 데이터에 대한 결과를 각각 나타내었으며, 평가는 테스트 데이터에 대한 R2 score와 RMSE 결과를 이용하였다. 3가지 모델 중 일반화 성능 및 테스트 데이터에 대한 예측 성능은 RF가 가장 우수한 것을 Fig. 3(a)를 통해서 알 수 있다. 그에 반해서, Fig. 3(b)를 보면 XGB는 과대적합으로 인해서 학습데이터에 대한 예측 성능은 우수하나 테스트 데이터에 대한 예측 성능이 낮다는 것을 알 수 있다. XGB 모델은 반복적으로 잔차(residual error)를 줄이는 방향으로 학습이 되기 때문에 학습 데이터에 대해서는 예측 성능이 좋다. 하지만 데이터가 적은 경우, 일반화 성능이 낮기 때문에 학습이 잘된 XGB 모델임에도 불구하고 테스트 데이터에 대해서는 예측 성능이 낮은 과대적합을 보일 수 있다. Fig. 3(c)의 SVR 결과는 일반화 성능과 테스트 데이터에 대한 예측 성능 모두 가장 낮은 값을 보이고 있다. 특히 SVR 모델의 경우에는, 낮은 포화자화값과 높은 포화자화값 부분에서 예측 성능이 좋지 않음을 알 수 있다.
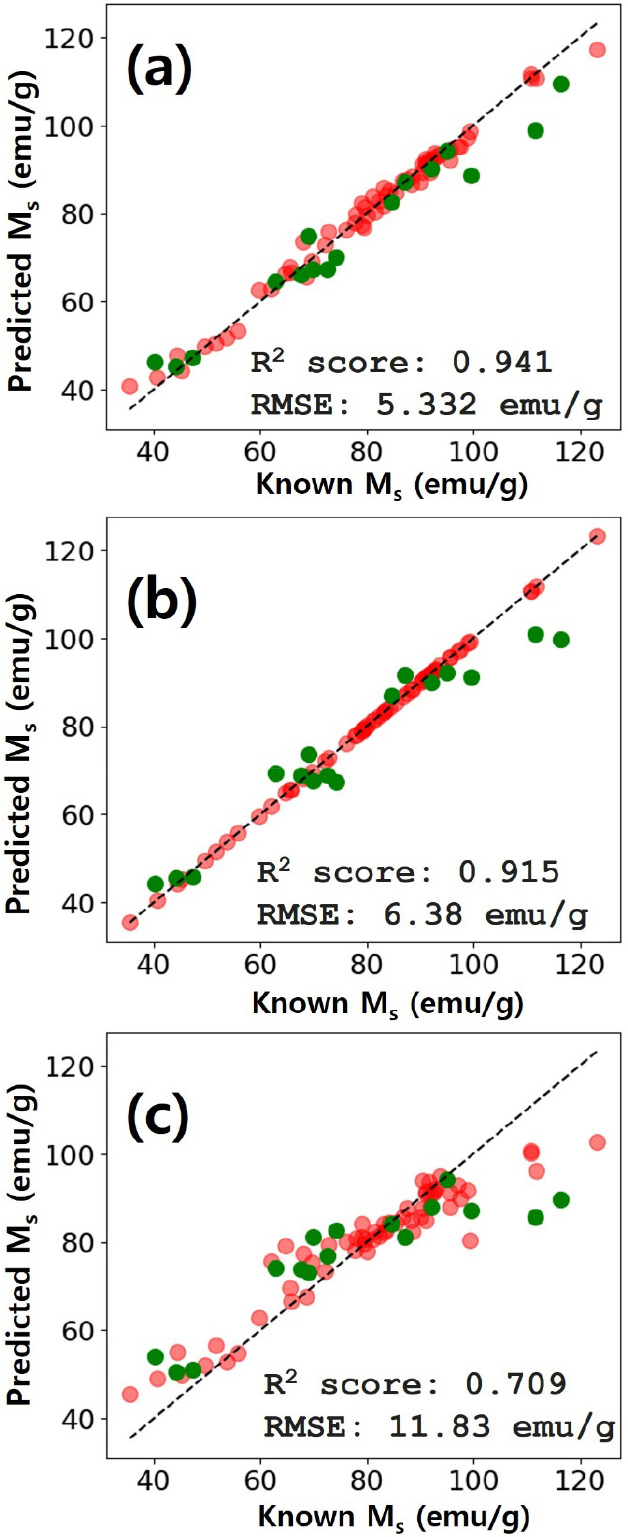
Fig. 4(a)는 가장 우수한 예측 성능을 보인 RF 모델을 이용하여 순열 기반 특성인자 중요도 탐색법으로 찾은 20개의 특성인자의 순서를 중요한 것부터 차례대로 나타낸 것이다.10) 순열 기반 특성인자 중요도 탐색법은 각 특성인자에 대해서 무작위로 섞었을 경우, 예측 성능이 얼마나 감소하는지에 따라서 주요 특성인자를 탐색하는 방법이다. 이 방법은 모델 자체의 구조에 의존하지 않고, 모델이 실제로 해당 특성을 얼마나 활용하는지를 직관적으로 반영한다. Fig. 4(a)의 y축 값은 무작위로 섞었을 때 얼마나 예측 성능이 감소하는지를 보여준다. 즉 RF 모델의 예측 결과에서, 특성인자가 중요할수록 무작위로 섞었을 때, 예측 성능이 급격히 감소하는 것을 알 수 있다.
가장 중요한 특성인자는 “Magpie avg_dev Mendeleev Number”이며, 이것은 조성 내에 포함된 원소들의 멘델레예프 번호가 평균값에서 얼마나 벗어나 있는지를 측정한 값을 나타낸다.9) 아래 식 (3)을 통해서 그 값이 얻어진다.
위 식 (3)에서 는 i번째 원소의 조성 비율을 나타내며, 는 i번째 원소의 Mendeleev Number를 의미하고, 는 조성 전체의 Mendeleev Number 평균을 나타낸다.
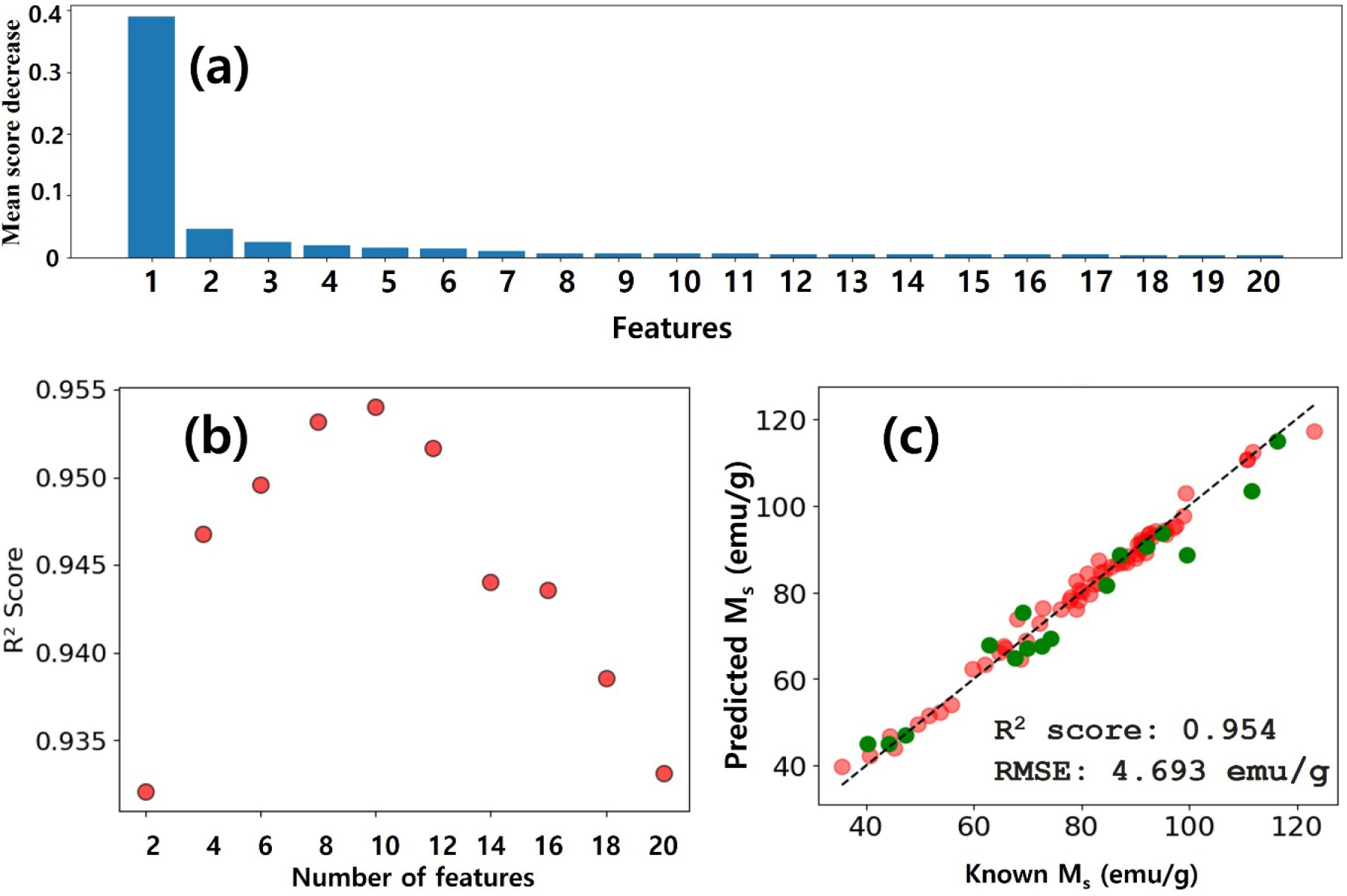
Fig. 4.
(a) Feature importance plot of the RF regression model, showing the top 20 most influential features. (b) Variation in RF model prediction performance as a function of the number of features selected via the permutation feature importance method. (c) Parity plot comparing the predicted and actual saturation magnetization values using the RF model optimized with 10 features.
Fig. 4(b)는 permutation feature importance 순서에 따라서 얻어진 20개의 특성인자를 중요한 순서부터 2, 4, 6, 8, 10, 12, 14, 16, 18, 20개로 나누어 특성인자 수에 따른 RF 모델의 학습한 후 테스트 데이터에 대한 예측 성능지표인 R2 score를 보여준다. 성분기반 특성인자 10개를 사용했을 경우 가장 우수한 예측 성능을 보여주고 있으며, 그에 대한 예측 성능(parity plot)은 Fig. 4(c)에 나타난다. 예측 성능지표인 R2 score는 0.954이며, RMSE는 4.693 emu/g이다. 학습데이터의 일반화 특성도 우수하며, 테스트 데이터에 대한 예측 성능도 전체 특성인자를 사용했을 경우보다 높다는 것을 알 수 있다.
기계학습의 우수한 예측 성능을 얻기 위해서는, 입력데이터에 사용되는 특성인자를 적절하게 선택하는 것이 중요하다. 특성인자를 많이 사용하면 과대적합이 일어나며, 또한 특성인자 수를 줄이는 과정에서 중요한 특성인자를 사용하지 않는 경우에는 예측 성능이 감소하게 된다. 트리기반 앙상블 알고리즘인 RF의 경우에는 과대적합을 줄이기 위해서, 특성인자수를 줄이기 위해서 순열 기반 특성인자 중요도 탐색법을 적용하였으나, 특성인자간의 비선형 관계성이 있기 때문에 이 방법만으로는 최적화하는데 한계가 있다. 본 연구에서는 과대적합을 줄이기 위해서 특성인자를 10개로 줄였지만, 최적화의 또다른 방법인 유전알고리즘을 이용해서 20개의 특성인자에서 주요한 특성인자를 재탐색하였다.11) 유전 알고리즘은 적합도 함수(fitness function)를 사용하여, 부모세대에서 우수한 특성인자를 확인하고 교배(crossover)와 돌연변이(mutation)을 이용하여 더 우수한 특성인자들로 이루어진 군(group)을 찾는 방법으로 진행하였다. 유전알고리즘에서 개별 특성인자는 (1,0)을 갖는 binary data로 변환하여 특성인자의 선택(1) 및 미선택(0)으로 구분하였으며, 여러 경우에 대해서 적합도 함수를 적용하여 최적의 특성인자가 찾아지도록 하였다. 본 연구에서 사용한 유전알고리즘의 파라미터는 Table 2에 나타내었다. 유전 알고리즘의 구체적인 조건은 다음과 같다. 전체 세대는 100세대를 통해서 최종 값을 확인하였으며, 각 세대마다 인구수(특성인자 조합 수)는 50으로 하였다. ‘Elite ratio’ 는 0.01로 하여 우수한 특성인자 조합에 해당하는 1 %는 변형 없이 다음세대로 추천하는 방식을 택하였다. 다음 세대를 구성하기 위해서 사용된 교배비율은 0.5로 하고 교차 방법은 ‘uniform’으로 하여 부모세대의 교차 50%가 무작위로 진행되도록 하였다. 마지막으로 다음 세대를 구성하기 위해서 사용된 돌연변이 비율은 0.1로 하여 10 %의 특성인자는 무작위로 바뀌도록 하여서 다양성이 유지되도록 하였다. 유전알고리즘에 대한 개략도는 Fig. 5에 나타내었다. 사용된 20개의 특성인자 가운데, 순서에 관계없이 1개부터 20개의 특성인자를 선택할 수 있는 조합의 수는 식 (4)와 같이 계산하면 총 1,048,575개에 해당한다. 조합의 수를 줄여서 최적해를 구하기 위해서 permutation importance에서 찾은 중요 특성인자 첫 번째와 두 번째는 고정하여 사용하고 나머지 18개에서 0개부터 18개를 선택하는 방법으로 식 (5)와 같이 계산된 262,144 조합 가운데 최적화 특성인자를 찾는 방법으로 유전알고리즘을 적용하였다.
Table 2.
Parameters Used in the Genetic Algorithm.
| parameters | conditions |
| max_num_iteration | 100 |
| population_size | 50 |
| elite_ratio | 0.01 |
| crossover_probability | 0.5 |
| parents_portion | 0.3 |
| crossover_type | uniform |
| mutation_probability | 0.1 |
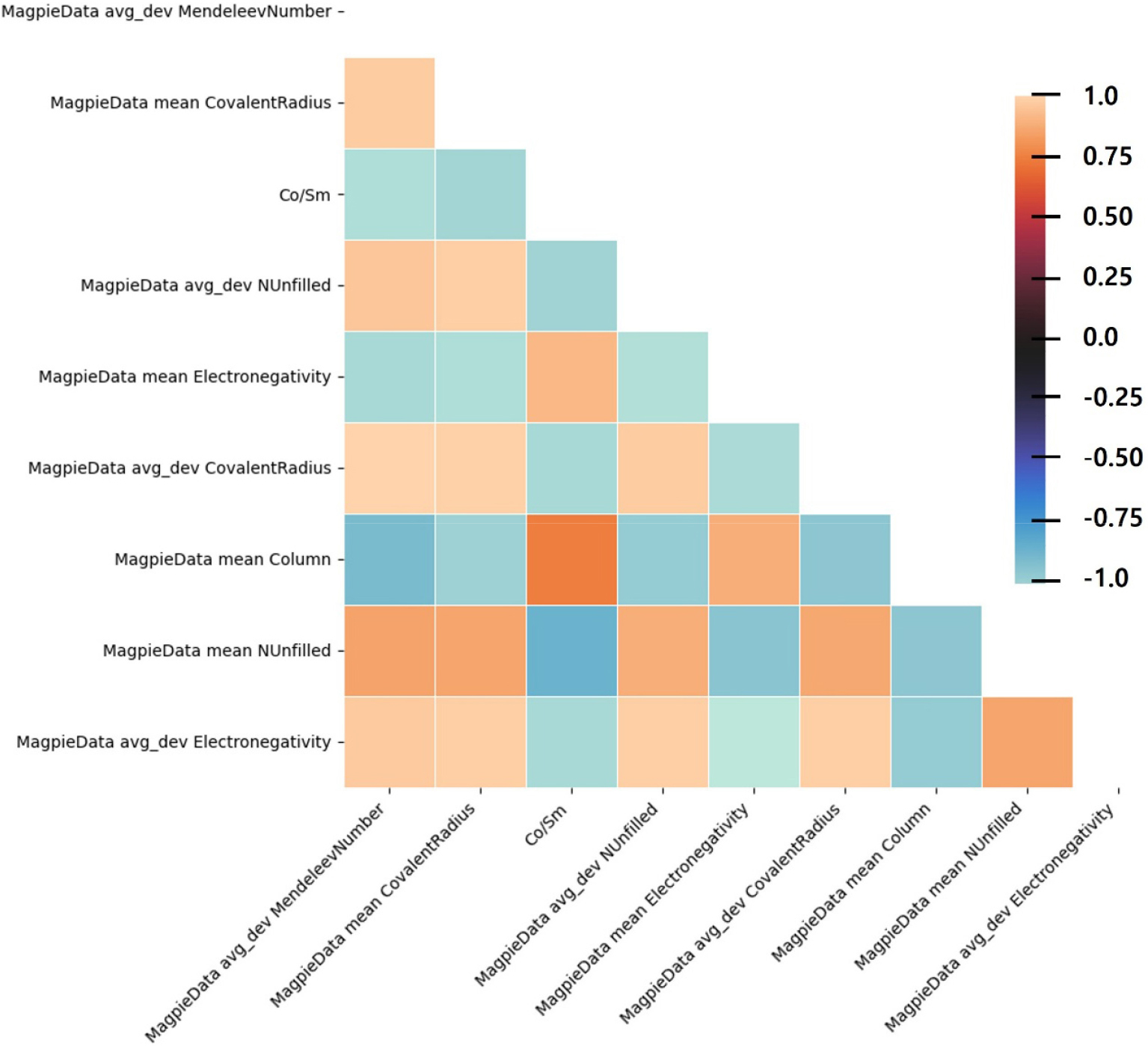
Fig. 6(a)는 유전알고리즘을 통해서 100세대를 거치는 동안 각 세대마다 얻어진 fitness 함수의 비용함수인 RMSE의 변화를 보여준다. 세대를 거치는 동안 비용함수는 감소하면서 최적화 과정이 이루어지는 것을 알 수 있다. 성능지표 RMSE는 초기조건에서 4.602 emu/g 값으로 시작하여 최종적으로 4.220 emu/g 값을 얻을 수 있었다. 유전알고리즘을 통해서 최종적으로 얻어진 특성인자는 9개가 선택되었으며 Table 3에 나타내었다. 9개 특성인자에 대한 피어슨 상관관계 계수에 대한 그림은 Fig. 7에 나타나 있다. Fig. 6(b)는 유전알고리즘을 얻은 최적의 특성인자 9개를 바탕으로 RF 모델을 학습하고 테스트 데이터에 대한 예측 성능을 확인한 것이다. 성능지표인 R2 score는 0.963이며, RMSE는 4.220 emu/g으로 가장 우수한 결과를 보이는 것을 확인할 수 있다. 전체적인 포화 자화값에 대해서 잘 예측하는 것을 확인할 수 있으며, 이를 통해서 유전알고리즘을 통한 특성인자 선택이 유효하게 작동하고 있음을 확인할 수 있다.
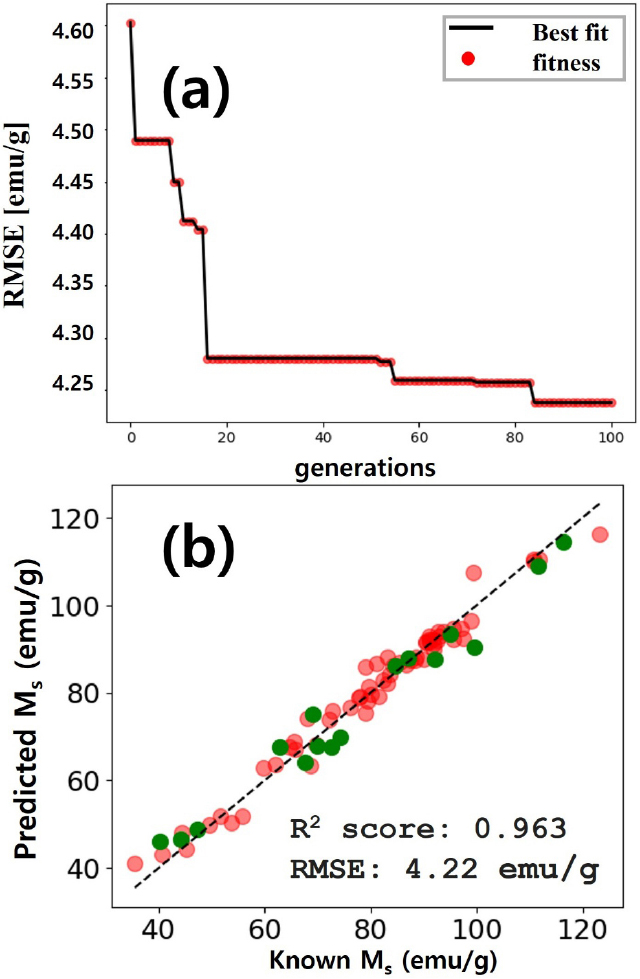
Table 3.
Selected features by the genetic algorithm.
4. 결 론
본 연구에서는 참고문헌4)에서 제공되는 SmCo 영구자석의 자성 특성 데이터를 바탕으로 RF, XGB, SVR의 기계학습 모델을 이용하여 예측 성능을 확인하고 RF가 가장 우수한 회귀 예측 성능을 나타내는 것을 확인하였다. 조성기반 특성인자를 바탕으로 예측 성능을 확인하였으며, 과대적합을 막기 위해서 순열 기반 특성인자 중요도 탐색과 유전알고리즘을 이용하여 최종 9개의 특성인자를 선택하여 RF 모델의 최적화를 달성하였다. 조성기반 특성인자만으로 SmCo 영구자석 포화 자화값을 우수하게 예측하여 R2 score는 0.963, RMSE는 4.22 emu/g 를 얻었다.
