

1. 서 론
고엔트로피 합금(high-entropy alloys, HEA)은 5개 이상의 원소를 포함하고 각 원소의 비율이 5 %~35 % 사이인 주요 원소를 5개 이상 포함하는 합금으로 정의된다.1) HEA은 높은 강도2)와 우수한 내마모성3) 등 뛰어난 물성을 나타낸다. 따라서 2004년에4) 발견된 이후 HEA는 지속적인 연구의 대상이 되어 왔다.
기존 연구에 따르면, 60개의 매우 보수적인 추정으로 사용 가능한 원소로부터 약 10100개의 HEA을 구성할 수 있는 것으로 추정된다.5) 실험적 혹은 계산적 탐색 과정에서 소요 시간과 자원이 급격히 증가하여 최적 조성을 찾는 것이 매우 난해하다. 따라서 앞서 언급한 실험과 계산 기법만으로는 여전히 방대한 조성 공간을 모두 탐색하기에 시간과 비용 부담이 막대하다. 이러한 한계를 극복하기 위해 최근에는 기계학습을 접목한 데이터 주도적 접근이 각광받고 있으며, 이는 최소한의 실험 및 시뮬레이션 결과를 활용해 조성-특성 관계를 학습하여 물성을 예측하고 잠재적으로 우수한 HEA 후보를 신속히 선정하는 데 핵심 역할을 하고 있다.
최근 보고된 연구 사례 가운데 하나로, 36개의 물리 야금 특성을 포함한 1,460개 데이터셋을 기반으로 랜덤 포레스트(random forest, RF), 서포트 벡터 머신(support vector machine, SVM) 등 8종의 분류기를 학습하여 HEA의 FCC, BCC, FCC + BCC 상을 예측하였고 97 % 이상의 정확도를 달성하였다.6) 또한, 자체 CALPHAD 데이터베이스에서 생성한 4억 8천만 개의 조성-온도 샘플을 학습데이터를 사용하여 Cr-Hf-Mo-Nb-Ta-Ti-V-W-Zr 9개 원소 시스템을 가지는 고엔트로피 합금의 상(phase) 분율을 초고속으로 예측하는 대리 모델(surrogate model)을 개발하였다. RF는 보간 구간에서 낮은 오차를 보였고, 딥러닝 신경망(deep neural network, DNN)은 고차원 조성으로의 외삽에서 우수한 일반화 성능을 보여 대규모 HEA 탐색 파이프라인의 핵심 모듈로 활용 가능함을 입증하였다.7) 또 다른 연구에서는, 11개의 물리적 특성 기반 머신러닝 모델을 현상론적 규칙과 CALPHAD 모델링과 결합하여 Al-Cr-Nb-Ti-V-Zr 6개의 원소 시스템으로 이루어진 내열 고엔트로피 합금의 항복강도를 20~800 °C 범위에서 정밀하게 예측하였다.8) 한편, 다른 연구에서는 서로 다른 출처의 HEA 989개와 13개 설계 특성으로 DNN 분류기를 구축하고 베이지안 최적화(bayesian optimization)로 튜닝하여 4-fold 기준 정확도 84.75 %를 달성하였다. 상 라벨(phase label) 조건의 cGAN (conditional generative adversarial network)으로 150개 샘플을 증강해 재학습한 결과 정확도 93.17 %로 향상되었고, δ-ΔHmix 혼재 영역을 메우면서 SS와 SS+IM간 오분류가 크게 감소하였다. 또한 계층별 타당성 검사(layer-wise relevance propagation, LRP) 기반 해석에서 ΔHmix, δ, ΔSmix의 기여도가 높게 나타나 기존 경험 규칙과 합치했으며, 외부 신규 HEA 5종에도 높은 확률로 올바른 상을 예측했다.9)
그러나 위 연구들은 모두 물성 예측 모델을 구축한 뒤 그 결과를 활용해 기존 조성 공간에서 후보를 선별하는 단계까지만 수행하였다. 완전히 새로운 조성을 생성하고 탐색하는 생성 모델은 적용되지 않았다. 특히, 생성 모델을 역설계에 활용하여 목표 물성을 만족하는 신규 조성을 직접 도출하는 절차는 고려되지 않았다. 이러한 순방향 설계는 이미 존재하는 후보군 내에서만 탐색이 가능하므로 조성 공간이 제한적이다. 반면, 생성모델을 활용한 역설계는 학습된 잠재 공간을 기반으로 저차원에서 연속 최적화를 수행함으로써 사실상 무한한 연속 조성 공간까지 탐색할 수 있으며, 그 결과 기존 데이터에 존재하지 않는 완전히 새로운 합금 조합을 제안할 수 있다.
Table 1은 역설계 접근법을 이용해 새로운 합금 재료를 개발한 최근 연구들을 정리한 것이다. 대표적인 사례는 다음과 같다. Wasserstein 자동 인코더와 유전 알고리즘(genetic algorithm, GA) 및 입자 군집 최적화(particle swarm optimization, PSO)를 결합하여 Fe 기반 금속유리의 포화 자속 밀도(BS) > 1.5 T인 조성을 설계)하여 우수한 역설계 프레임워크를 제시하였다.10) 또 다른 사례로, 데이터 증강과 ResNet-기반 조건부 변분 자동 인코더-적대적 생성 신경망(conditional variational autoencoder-generative adversarial network, CVAE-GAN) 생성 모델을 결합해 ZT > 1.0 열전 재료 100종을 역설계하고, 그중 일부 시편을 실제 합성하여 300 K에서 ZT ≈ 0.75를 확인하였다.11) 이어, 확산 모델과 앙상블 머신러닝을 결합해 7xxx계 Al-Zn-Mg-Cu 합금의 최대 인장 강도(ultimate tensile strength, UTS)를 예측・최적화하여 750 MPa 이상의 고강도 후보 조성 세 개를 역설계하였다.12) 또한, 변분 자동 인코더(variational autoencoder, VAE)와 물성 예측기를 결합한 역설계 모델을 통해 Fe-Zr-Ni-Cu 기반 금속유리의 우수한 유리형성능(glass-forming ability, GFA)을 가진 조성을 생성하였다.13)
Table 1.
Summary of materials inverse design studies using machine learning.
| Year | Number of data | Alloy system | Feature | Target | ML algorithms | Inverse design | Reference |
| 2025 | 574 | Fe-based metallic glasses | Composition | Bs | MLP | WAE | 10) |
| 2025 | > 3,000 | Thermoelectric Materials | Composition | ZT |
LGB model DopNet ElemNet | cVAE-GAN | 11) |
| 2024 | 423 | 7xxxSeries Aluminum | Composition | UTS | Ensemble Model | Diffusion | 12) |
| 2024 | 7,380 | Metallic glasses | Composition | GFA | XGBoost | VAE | 13) |
그러나 기존 역설계 연구는 대부분 금속유리나 특정 Al 기반 합금 등 한정된 시스템을 대상으로 수행되어, 다원소 및 다상 구조가 복잡한 HEA 설계로 직접 확장되지 못하였다. 특히 연속 잠재 공간을 활용해 새로운 조성을 생성할 수 있는 VAE는 HEA 분야에서 아직 적용 사례가 없다. 또한 기존 연구들은 BS, 열전 특성, GFA 등 일부 지표에 집중되어 있어 HEA의 강도를 대상으로 한 최적화 연구는 아직 초기 단계에 머무르고 있다. 이러한 한계로 인해 방대한 HEA 조성 공간을 체계적으로 탐색하고 고강도 신규 조성을 발굴하려면, VAE 기반의 데이터 주도 역설계 프레임워크가 필수적이다.
본 연구에서는 UTS 향상을 목표로 하는 생성모델 활용 HEA 역설계 프레임워크를 제안한다. 문헌에서 수집한 501개의 HEA 데이터를 기반으로 먼저 통계 분석을 수행해 데이터 특성을 파악하였다. 이후 그래디언트 부스팅(extreme gradient boosting, XGB), RF 두 가지 모델의 하이퍼파라미터를 베이지안 최적화로 조정한 뒤 DNN을 포함한 세 가지 모델의 성능을 비교하여 최적 예측 모델로 XGB를 선정하였다. 다음 단계에서는 PyTorch 기반 VAE를 학습하고 잠재 공간에서 고강도 영역을 목표로 샘플링해 새로운 조성을 생성하고 XGB 모델을 통해 평가하였다. 마지막으로 샤플리 부가 설명(shapley additive explanations, SHAP) 해석과 네트워크 플롯을 통해 각 특성 인자의 기여도와 상호작용을 정량화해 모델 기반 설계가 제안한 조성의 물리적 타당성을 확인하였다.
본 논문의 구성은 다음과 같다. 2장은 데이터 구축, 모델 학습과 최적화, VAE 역설계 전략을 포함한 연구 방법론을 상세히 설명한다. 3장에서는 모델 성능, SHAP 해석 결과, VAE 생성 조성의 분포 및 예측 강도 분석을 다룬 후 마지막으로 연구 결과를 종합적으로 논의하고, 본 프레임워크의 의의를 제시한다.
2. 실험 방법
Fig. 1은 본 연구의 프레임워크를 나타낸 그림이다. 본 연구는 3단계로 구성되어 있다. 첫째 HEA 데이터를 문헌들로부터 수집하였으며 데이터에는 합금의 조성 비율과 실험 조건, 최대 인장 강도 물성을 포함하고 있다.14) 피어슨 상관계수(Pearson’s correlation coefficient, PCC)를 포함한 데이터에 대한 통계적 분석도 함께 진행되었다. 둘째 최대 인장 강도에 대해 여러 기계학습 모델을 하이퍼파라미터 최적화 기반으로 학습한 후, 예측성능이 가장 우수한 XGB 모델을 최종 선택하였다. 셋째 재료 역설계(materials inverse design)를 위한 VAE를 사용하여 HEA 소재를 설계하고 학습한 XGB 모델로 최대 인장 강도를 예측하였다.
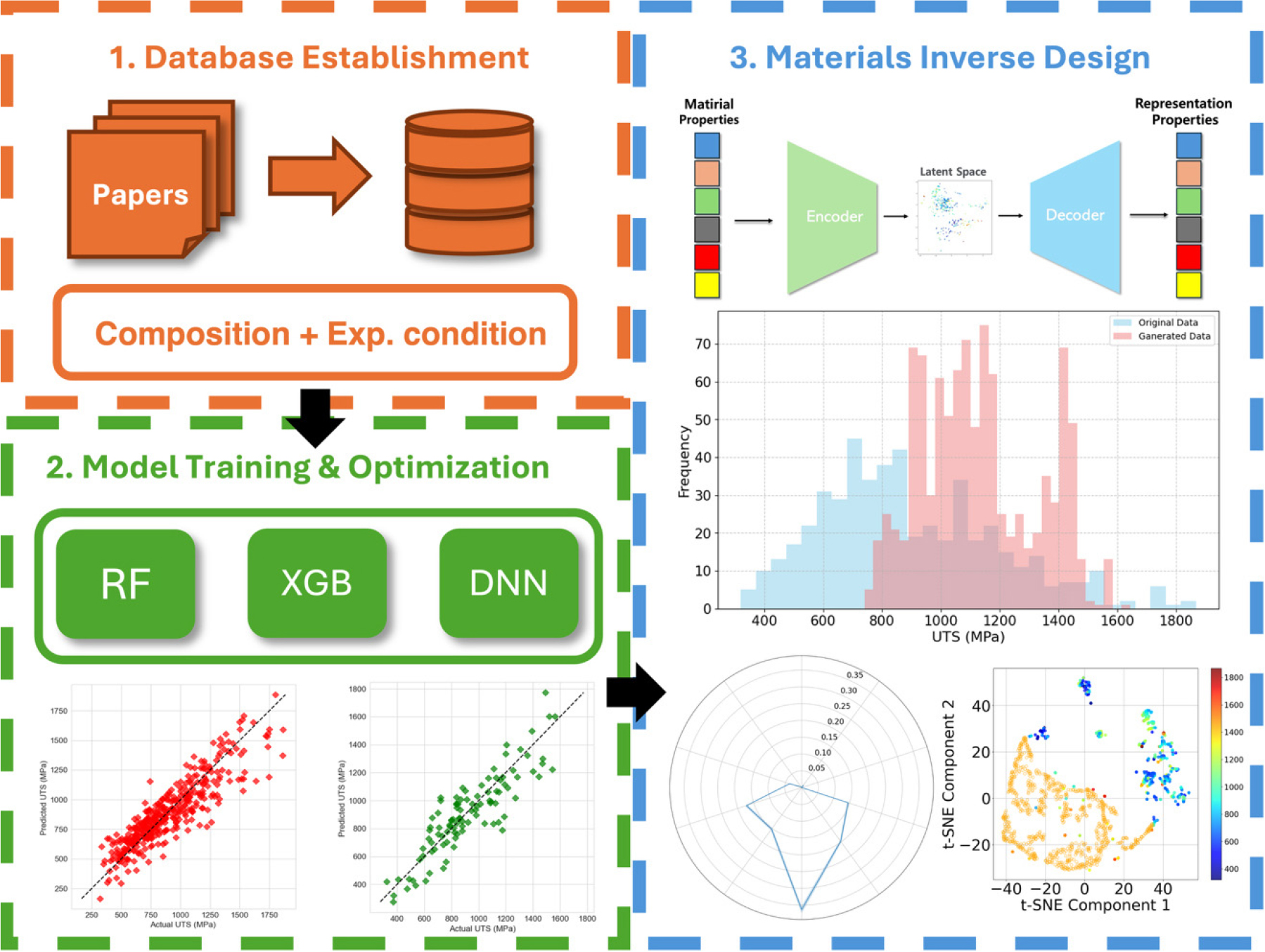
2.1. 소재 데이터
본 연구에서 사용된 소재 데이터는 이전 문헌들로부터 수집된 501개의 HEA 소재 데이터가 사용된다.14) 해당 데이터셋은 C, Al, V, Cr, Mn, Fe, Co, Ni, Cu, Mo의 10가지 원소 시스템의 HEA의 조성과 기계적 특성과 다음 4가지 실험 조건을 포함하고 있다.
∙ 균질화 온도(homogenization temperature)
∙ 냉간 압연율(reduction rate)
∙ 열처리 온도(annealing temperature)
∙ 열처리 시간(annealing time)
균질화 온도는 0 K에서 1,573 K, 냉간 압연율은 0 % 에서 96 %, 열처리 온도는 0 K에서 1,573 K, 열처리 시간은 0 h에서 50 h로 구성되어 있다. 전체 데이터에 대한 자세한 통계적 데이터는 Table 2에 나와 있으며, 각 특성에 대한 최대값, 최소값, 평균값이 포함되어 있다. Fig. 2는 501개의 HEA 소재의 최대 인장 강도를 보여준다. UTS는 약 320 MPa에서 1,867 MPa까지 분포하고 있다. Fig. 2에서 붉은 점선은 최대 인장 강도가 상위 25 %에 해당하는 지점이며, 그 기준값은 1,090 MPa이다. 이 구간에 포함되는 데이터는 총 126개이다.
Table 2.
Statistics of the dataset.
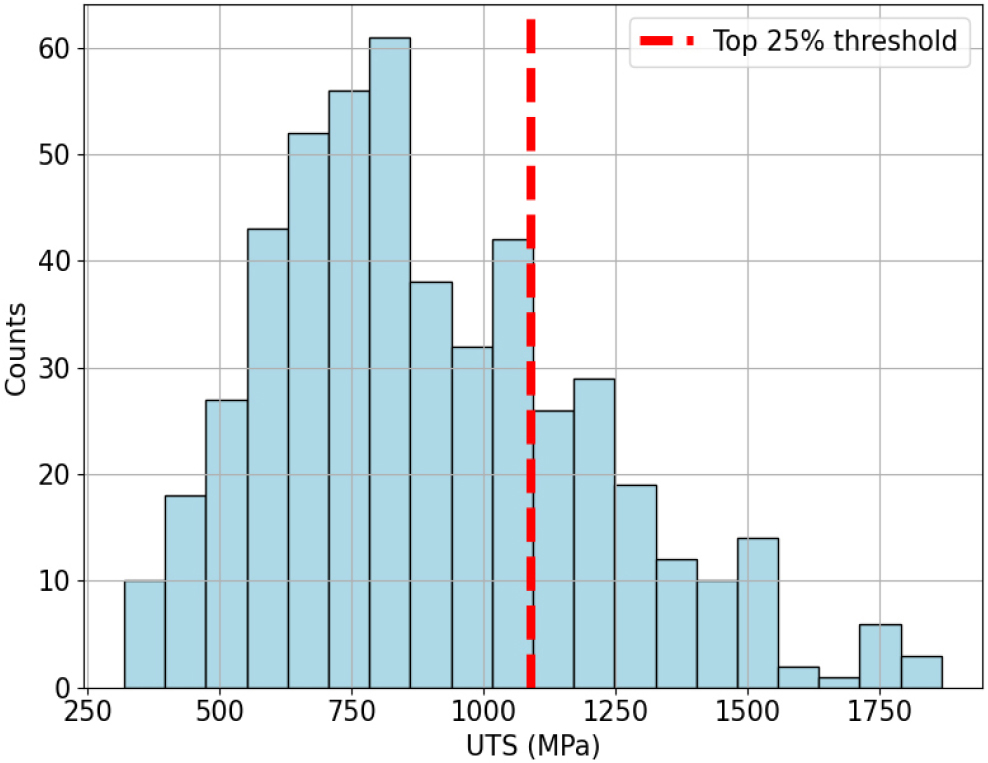
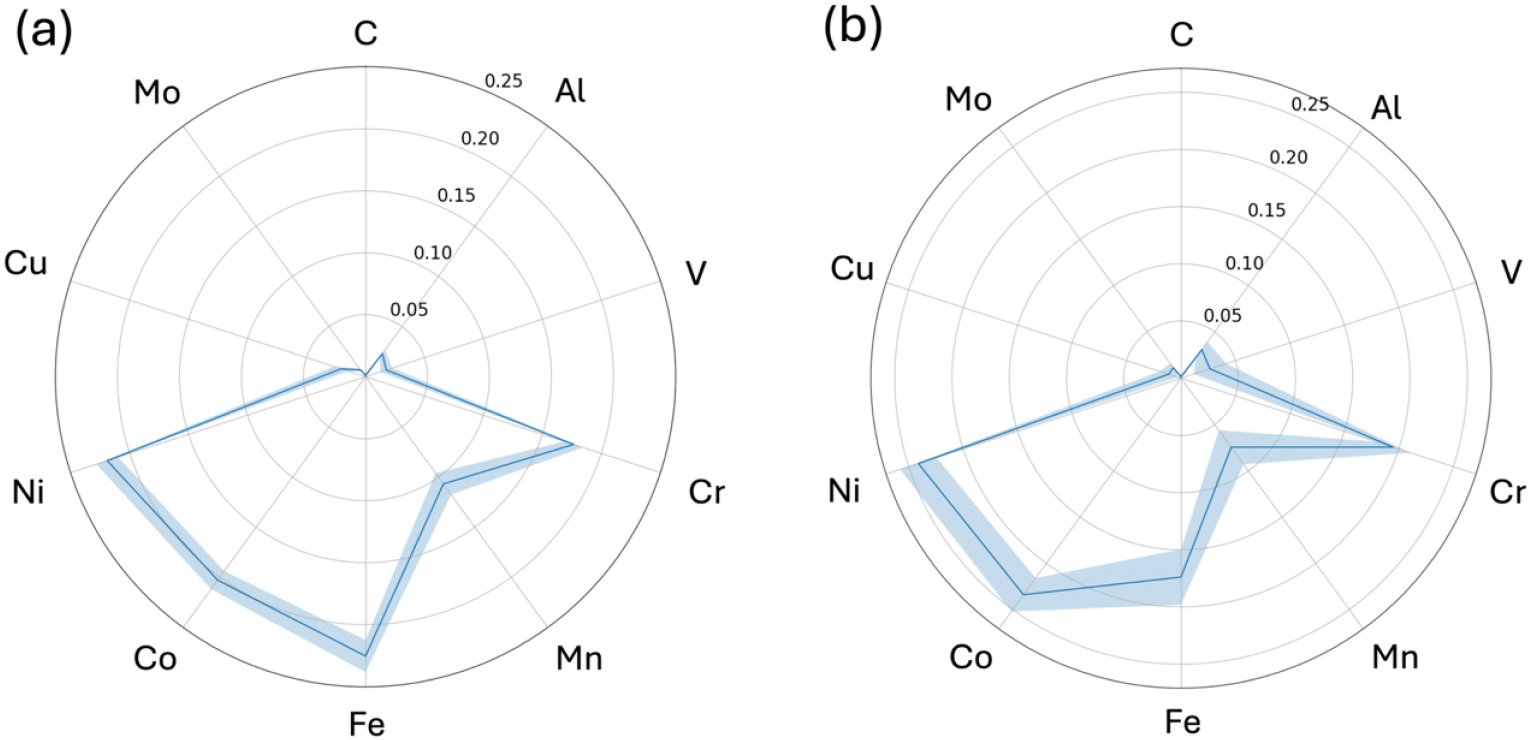
Fig. 3에 제시된 레이더 플롯은 데이터셋에 포함된 합금들의 화학적 조성과 실험 조건의 분포를 보여준다. Fig. 3(a)을 보면 데이터셋 내에서 Fe, Ni, Co, Cr, Mn은 평균적으로 높은 조성 비율을 가진다. 이는 이들 원소가 HEA의 핵심 구성 성분임을 확인할 수 있다. 반면, C, V, Mo, Al, Cu 등의 원소들은 조성 평균 비율이 낮게 나타난다. 이는 이들 원소가 주원소가 아니고 합금의 미세조직 제어, 기계적 특성 개선 등의 특정 목적을 가지고 소량 첨가되었음을 시사한다. Fig. 3(b)는 목표 값이 높은 상위 25 % 합금들에 대한 레이더 플롯이다. 최대 인장 강도가 높은 데이터만을 분석한 결과, Fe와 Mn의 평균 함량은 상대적으로 낮은 반면, Cr의 평균 함량은 소폭 증가하는 경향을 보였다.
조성과 4가지 실험 조건을 포함한 14가지 특성들 간의 상관관계를 파악하기 위해 PCC를 사용하였다. Fig. 4는 14가지 특성의 PCC 매트릭스이다. PCC를 계산하기 위해 식(1)이 사용되었다.
여기서 와 는 두 특성의 번째 관측값이며, 와 는 각각 그 특성들의 평균을 나타낸다. n은 전체 데이터 수를 나타낸다. PCC 값은 +1에서 -1까지의 범위를 가지며, 양의 값은 양의 상관관계를, 음의 값은 음의 상관관계를 의미한다. 여기서 분자는 두 특성들 간의 공분산(covariance)을 나타내며, 분모는 각각의 표준편차를 곱한 값이다. 기존 연구에 따르면 두 특징의 상관계수가 0.8 이상인 경우 중요도가 높은 특성만을 유지한다.15) 하지만 Fig. 4의 PCC 히트맵에서 가장 높은 상관관계를 보이는 특성쌍은 Fe-Ni 간의 -0.71이다. 따라서 본 연구에서는 모든 특성 인자를 그대로 사용하였다. 가장 강한 양의 상관관계를 가지는 특성쌍은 냉간 압연율과 열처리 시간 사이의 0.64이며 가장 강한 음의 상관관계를 가지는 특성쌍은 Fe-Ni 간의 -0.71이다. Mn은 실험 조건 4가지의 전부 음의 상관관계를 가진다. 이는 실험 조건 값 높을수록 Mn의 함량은 낮아지고, 반대로 실험 조건 값 낮을수록 Mn의 함량은 높아지는 것을 의미한다.
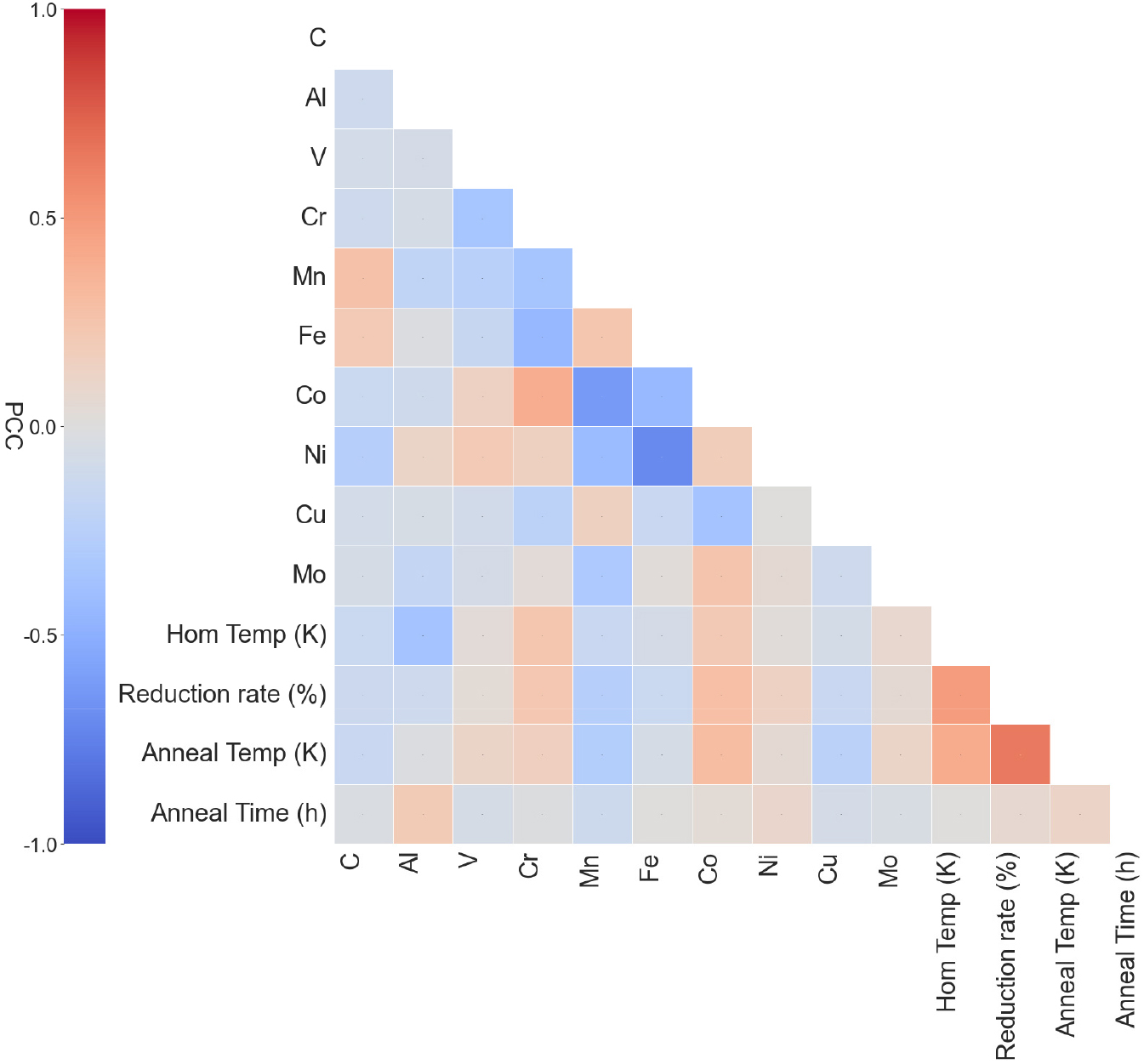
Fig. 5는 변수 중요도(variable importance, VImp)와 변수 상호작용(variable interaction, VInt)을 시각화한 네트워크 플롯(network plots)을 보여준다. 네트워크 플롯에서 각 특성은 하나의 노드로 표시되며, 각 쌍의 상호작용은 엣지로 표현된다. 노드의 크기와 색상의 밝기는 VImp 값에 비례하여 커지고 밝아진다.16) 각 원소를 연결하는 선이 밝을수록 높은 상호작용을 의미하고, 상대적 크기는 색깔표로 나타내었다.
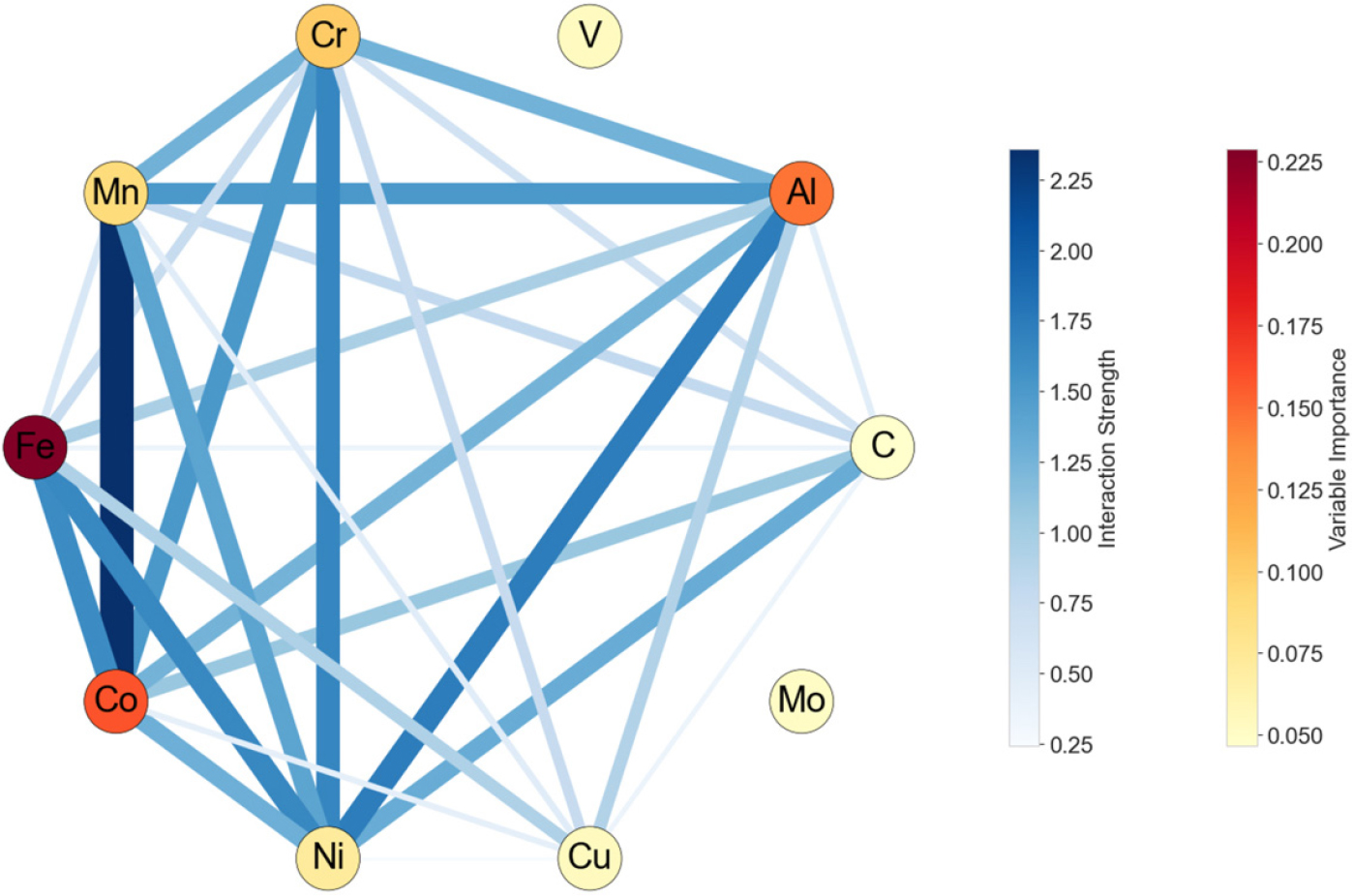
Fig. 5를 보면 Fe와 Al이 가장 높은 변수 중요도를 가지는 것을 볼 수 있다. Fe의 첨가는 고엔트로피 합금의 설계비용을 절감하는 효과가 있다.17) Al은 첨가 시 재료를 다상 구조로 변화시키며 Ni와 같이 첨가되면 석출상을 형성하여 강도를 향상시키고 연성을 감소시키는 효과가 있다.18,19)Fig. 5에서 Al과 Ni가 강한 상호작용을 가지는 것은 앞에서 설명한 기존 연구와도 일치한다. 변수 상호작용을 보면 Fe-Co, Co-Mn, Al-Ni 등 일부 조합이 모델 내 주요 상호작용을 보이는 변수 쌍임을 확인할 수 있다. 이 중 Co-Mn은 가장 강한 상호작용을 나타낸다. Fig. 5에서 Mo, V는 평균 함량이 낮고 네트워크에서 단독으로 존재하는 모습을 보인다. 이것은 다른 원소들과의 상호작용은 없지만 개별적으로 첨가되어 물성에 기여하는 것으로 이해할 수 있다. Mo는 다른 합금 원소보다 원자 반경이 크기 때문에, 격자 내 치환 위치를 차지함으로써 격자 왜곡을 증가시켜, 이는 추가적인 고용 강화(solid solution strengthening) 효과로 이어진다.20,21)
2.2. ML Model 학습 & 최적화
본 연구에서는 VAE를 이용해 생성된 데이터의 평가를 위해 최대 인장 강도를 예측하는 ML model을 학습하고 최적화하였다. 우리는 Keras와 scikit-learn을 활용해 RF, XGB, DNN 3가지 모델을 학습시키고 평가하였다. 모델의 평가는 전체 데이터셋을 80 % 학습용, 20 % 테스트용으로 분할하여 테스트용 데이터의 R2 Score와 평균 제곱근 오차(root-mean-squared-error, RMSE)를 확인하는 방식으로 수행되었으며 식 (2), (3)은 각각 R2 Score와 RMSE를 계산하는 수식이다.
DNN 모델은 입력으로 조성과 실험 조건을 포함한 14개 특성을 입력으로 사용하며, 3개의 은닉층과 드롭아웃 층으로 구성되고 ReLU 활성화 함수를 가지며 Table 3에 상세한 파라미터가 확인 가능하다. 학습은 100 에포크를 수행하였으며, 100번 반복하여 각기 다른 파라미터를 가지는 모델 100개를 얻었다. 학습된 100개 DNN 모델 중 테스트 데이터에 대한 R2 Score가 가장 높은 모델을 DNN 대표 모델로 선정하였다. XGB와 RF 모델의 최적화는 10-fold 교차검증을 기반으로 Bayesian optimization을 통해 수행하였다. 최종적으로 최적화된 모델의 하이퍼파라미터는 Table 3에서 확인할 수 있다.
Table 3.
Optimization method and optimized parameters for each model.
2.3. VAE Inverse Design
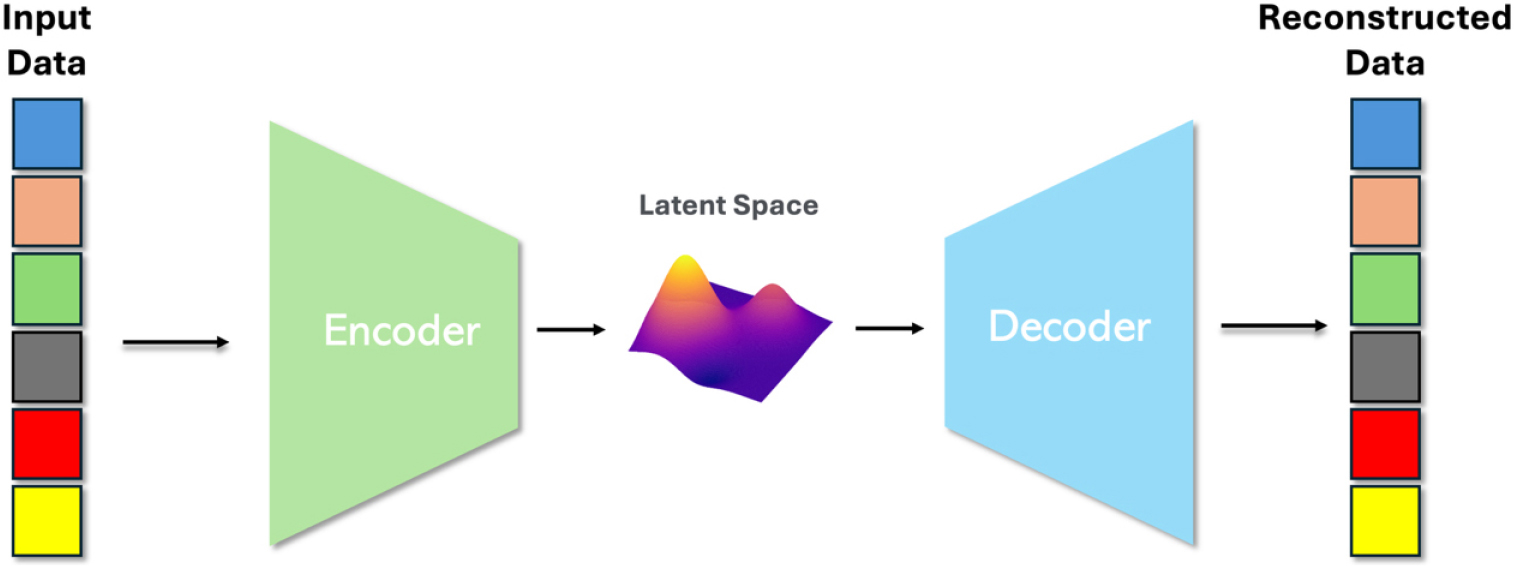
기계학습을 이용한 역설계(inverse design)는 새로운 재료를 발견하는 유망한 접근법으로 여겨져 왔다. VAE는 연속형 변수를 갖는 조성을 생성하기 위한 잠재 공간(latent space)을 만드는 데 사용될 수 있다. VAE는 자동인코더 구조 기반의 딥러닝 생성 모델이다. VAE는 입력한 데이터를 인코더를 통해 다변량 정규분포(multivariate normal distribution)를 따르는 확률변수로 매핑한다. 따라서 VAE의 잠재변수 Z는 입력 데이터의 확률분포를 의미한다. 이 분포로부터 샘플링된 잠재 변수 Z를 디코더에 입력하여 데이터를 재구축한다. 학습 과정에서는 재구성 오차와 정규분포와의 Kullback-Leibler 발산(KL divergence)을 최소화하는 손실 함수를 사용한다.
본 연구에서는 약 501개의 HEA 데이터셋을 활용하여 PyTorch 기반의 VAE 모델을 구성하고 학습시켰다. 화학적 조성 비율과 실험 조건 4가지를 입력변수로 사용하였다. 인코더 및 디코더는 다층 퍼셉트론(multi-layer-perceptron, MLP) 다층 구조로 구성된다. 모든 은닉층에는 ReLU 함수가 활성화 함수로 사용되었으며, 디코더의 출력층에는 softmax 함수가 사용되었다. 잠재 공간(latent space)은 2차원으로 설정하였다. VAE 구조는 Fig. 6에 나타나 있다. 소재 역설계 방식은 잠재 공간(latent space)의 상대적으로 높은 목표값 영역에서 1,000개의 Z를 중복 없이 랜덤으로 샘플링한 뒤 디코더에 입력하여 10개의 조성 비율과 4개의 실험 조건에 대한 데이터를 생성하는 방식으로 수행되었다. 이 내용은 결과 및 고찰에서 자세히 설명할 것이다.
3. 결과 및 고찰
Fig. 7은 각 모델의 학습과 실험데이터에 대한 패리티 플롯(parity plot)이다. DNN 모델은 테스트 데이터에 대해 0.791, 138.6 MPa의 R2 Score와 RMSE를 달성하였다. RF 모델과 XGB 모델은 각각 0.744, 143.3 MPa와 0.803, 125.9 MPa의 R2 Score와 RMSE를 달성하였다. 이를 통해 각 모델이 우수한 일반화 성능을 보임을 확인할 수 있다. 또한 전체 데이터셋을 대상으로 10-fold 교차검증을 수행한 결과, XGB는 RMSE 평균 174.152 MPa, R2 평균 0.5503을, RF는 RMSE 평균 181.296 MPa, R2 평균 0.4995를 기록하였다. 자세한 학습 데이터와 테스트 데이터에 대한 각 모델의 성능 지표는 Table 4와 Table 5에서 확인할 수 있다. 이 세 모델 중 가장 성능 지표가 좋은 XGB 모델을 최종적으로 예측 모델로 선택하였다.
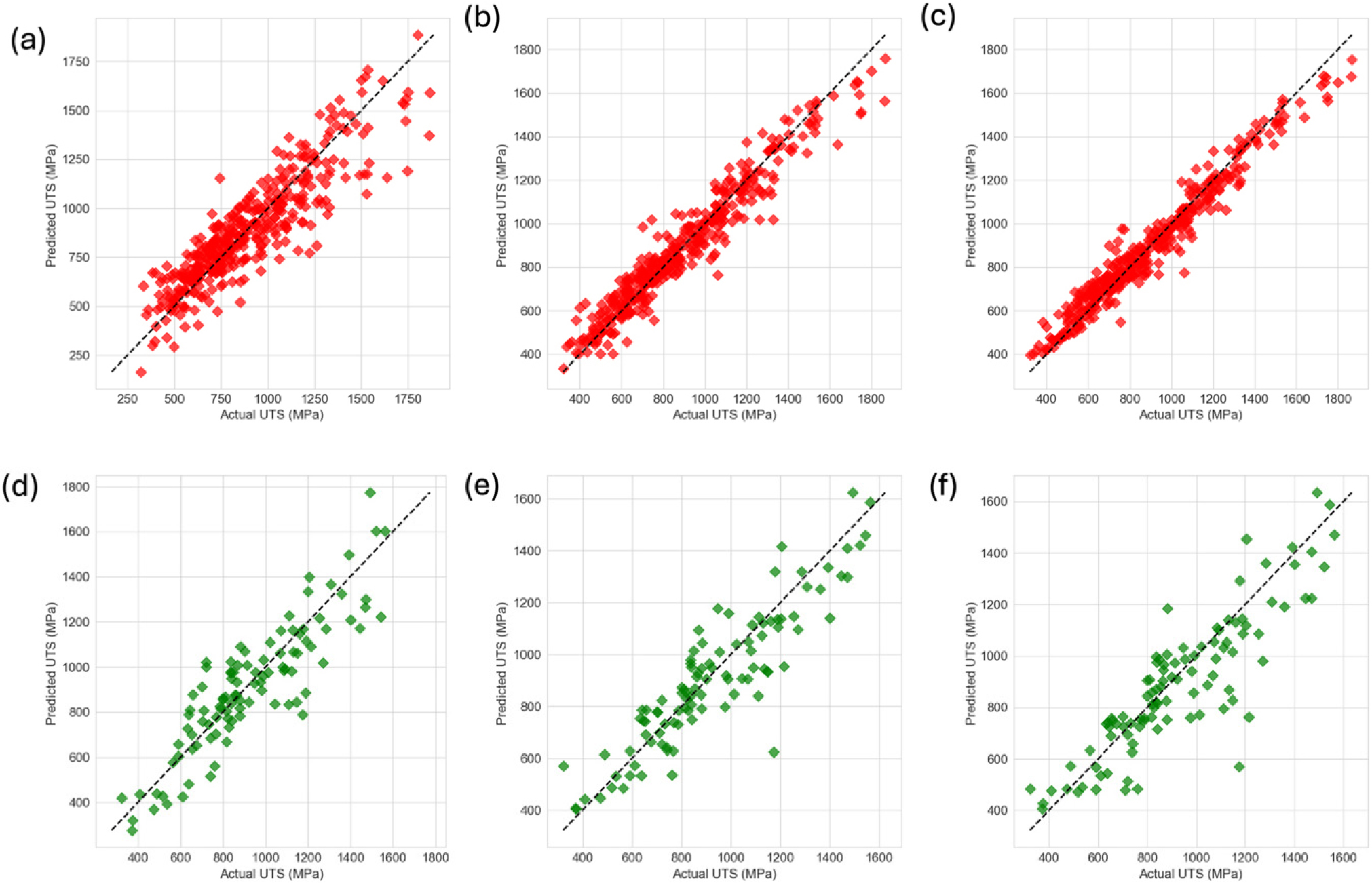
Table 4.
Performance metrics (R2 and RMSE) of each model on the training data.
| Model | R2 score | RMSE |
| DNN | 0.794 | 140.8 |
| XGB | 0.93 | 81.9 |
| RF | 0.953 | 67.3 |
Table 5.
Performance metrics (R2 and RMSE) of each model on the test data.
| Model | R2 score | RMSE |
| DNN | 0.761 | 138.6 |
| XGB | 0.803 | 125.9 |
| RF | 0.744 | 143.3 |
HEA의 조성과 UTS 간의 상관관계를 파악하기 위해 SHAP을 이용한 분석을 진행하였다. SHAP은 게임 이론을 바탕으로 각 예측에 대해 각 특성의 중요도를 할당하여 인공지능 모델에 대한 해석을 가능하게 하는 해석 기법이다.22) SHAP 값이 양수이면 그 특성 값이 모델이 산출한 목표 값을 높이는 방향으로 기여한다는 의미이며, 반대로 SHAP 값이 음수이면 해당 특성 값이 모델 예측을 낮추는 방향으로 기여함을 의미한다. Fig. 8은 최대 인장 강도를 목표 값으로 하여 특성별 SHAP 값을 나타낸 그림이다. 각 점은 한 조성에 대한 특정 특성의 SHAP 값을 나타내며, y축에서 겹치는 점은 수직 방향으로 퍼져서 SHAP 값 분포를 시각화한다. 냉간 압연율과 열처리 온도는 최대 인장 강도를 예측하는 데 있어 중요한 특성임이 분명하게 드러난다. Al, Co, Mo는 Fig. 3(a)에서 확인할 수 있듯이 평균적으로 낮은 함량을 가지지만, SHAP 분석에서는 높은 중요도를 가짐을 확인할 수 있다. SHAP 값을 살펴보면 냉간 압연율이 증가함에 따라 모델의 예측값을 높이는 방향으로 기여함을 확인할 수 있다. 냉간 압연은 고엔트로피 합금의 전위 밀도 증가와 쌍정을 통해 강도를 크게 향상시키지만, 일반적으로 연성을 감소시키는 강도-연성 상충 관계를 유발한다.23) 열처리 온도는 증가함에 따라 모델의 예측값을 낮추는 방향으로 기여한다.
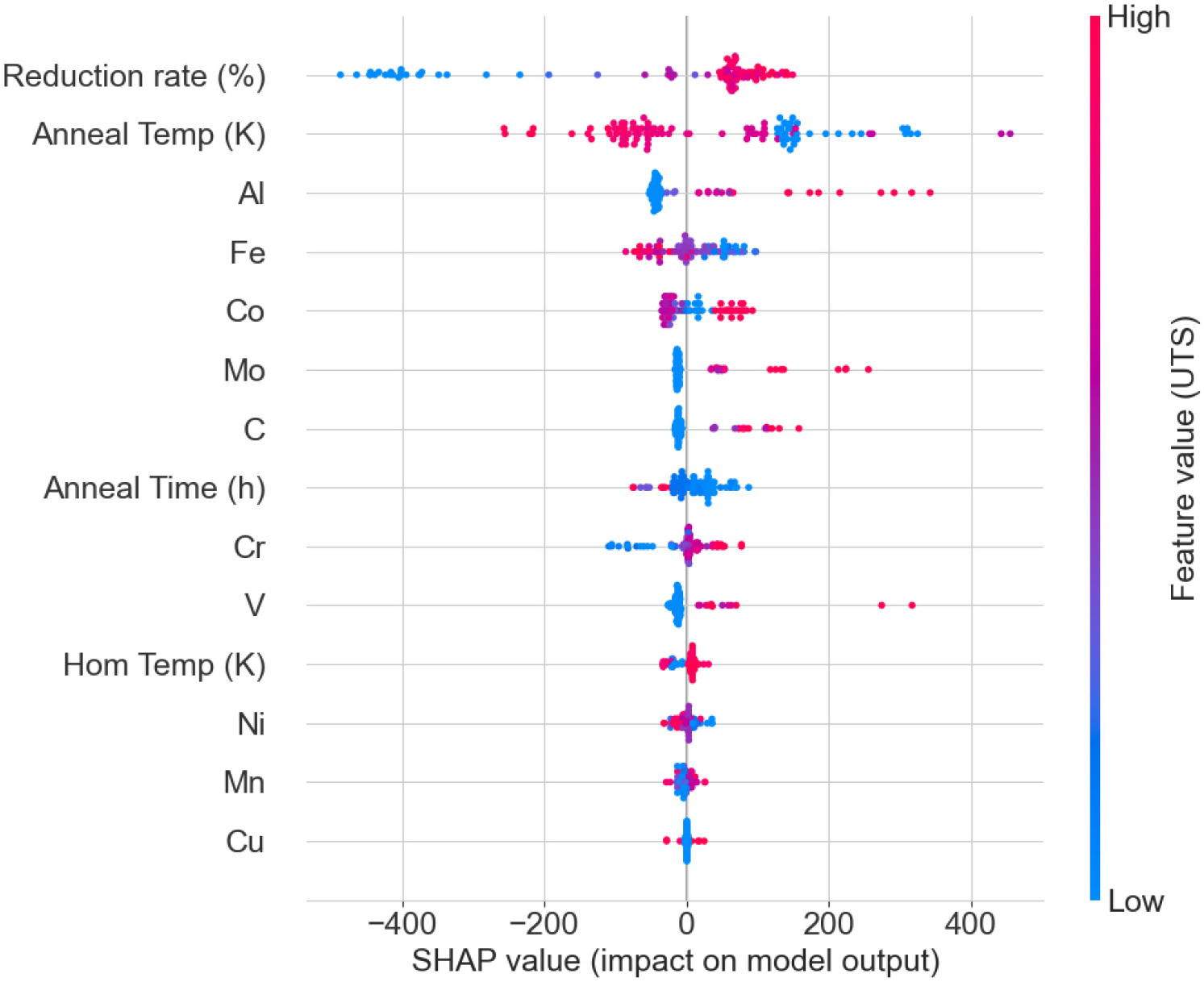
열처리 온도는 재결정화 정도, 결정립 크기, 전위 밀도에 직접적인 영향을 미치며, 이러한 미세구조 변화가 최종적인 강도-연성 균형 및 변형 경화 거동을 결정하게 된다. 또한 높은 열처리 온도는 재결정화를 촉진하고 결정립을 성장시켜 재료의 강도를 저하시키지만, 연성을 향상시키는 경향이 있다.24) Al의 증가는 모델의 예측값을 높이는 방향으로 기여하며 Al은 Ni와 같이 첨가되면 석출상을 형성하여 강도를 향상시키고 연성을 감소시키는 효과가 있음이 연구에서 입증되었다.
Fig. 9(a)는 학습된 VAE 모델의 잠재 공간(latent space)이다. 상단부에 높은 최대 인장 강도를 가지는 물질들의 확률분포와 낮은 강도를 가지는 물질들의 확률분포가 나누어져 있다. 최대 인장 강도가 높은 물질의 확률분포에서 1,000개의 Z를 무작위로 샘플링하여 디코더에 입력시켜 나온 생성 데이터이다. 생성된 데이터의 샘플링 영역은 Fig. 9(b)에서 확인할 수 있다.
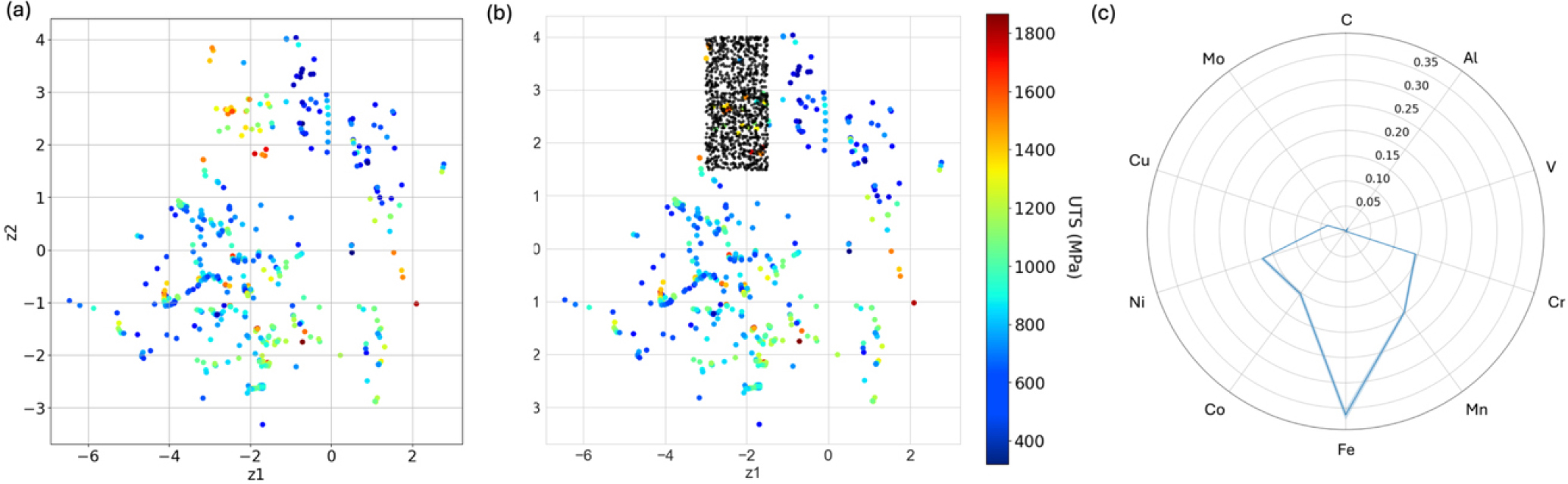
Fig. 9(c)는 VAE로 생성된 1,000개의 데이터의 조성에 대한 레이더 플롯이다. 생성된 데이터들은 Ni, Co, Fe, Mn, Cr가 평균적으로 높은 조성 비율을 가짐을 알 수 있다. Ni와 Fe 기반의 고엔트로피 합금은 우수한 최대 인장 강도를 나타내는 것이 확인되었다. 또한 HEA에 Cu를 첨가하면 강도와 연성을 동시에 향상시키는 효과가 있는 것으로 보고되었다. 학습 데이터와 비교하면 두 집단 모두 Ni, Co, Fe, Mn, Cr가 주요 원소라는 점은 동일하지만, 학습 데이터는 Ni, Co, Fe의 함량이 상대적으로 높고 Mn은 낮은 반면, 생성 데이터는 Ni, Co의 함량이 다소 줄고 Mn이 소폭 증가하는 경향을 확인하였다. 1,000개의 생성 샘플을 앞서 최적화된 XGB 모델을 통해 강도를 예측하였다. Fig. 10은 생성된 1,000개의 데이터에 대한 강도 예측값이다. 800~1,600 MPa 범위로 강도가 예측되는 걸로 보아 VAE 모델이 높은 강도를 가지는 물질의 확률분포를 잘 학습하였음을 알 수 있다.
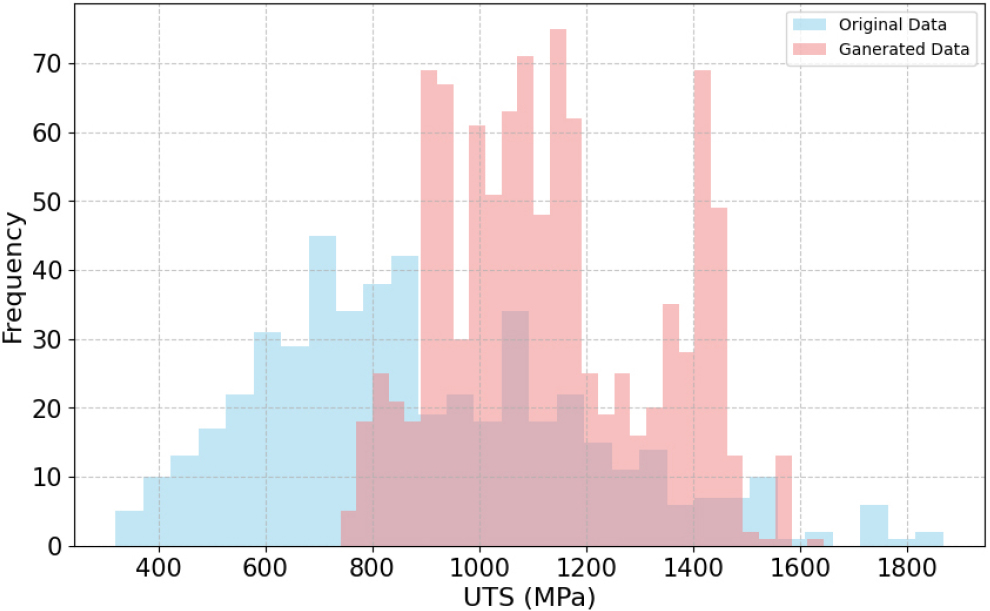
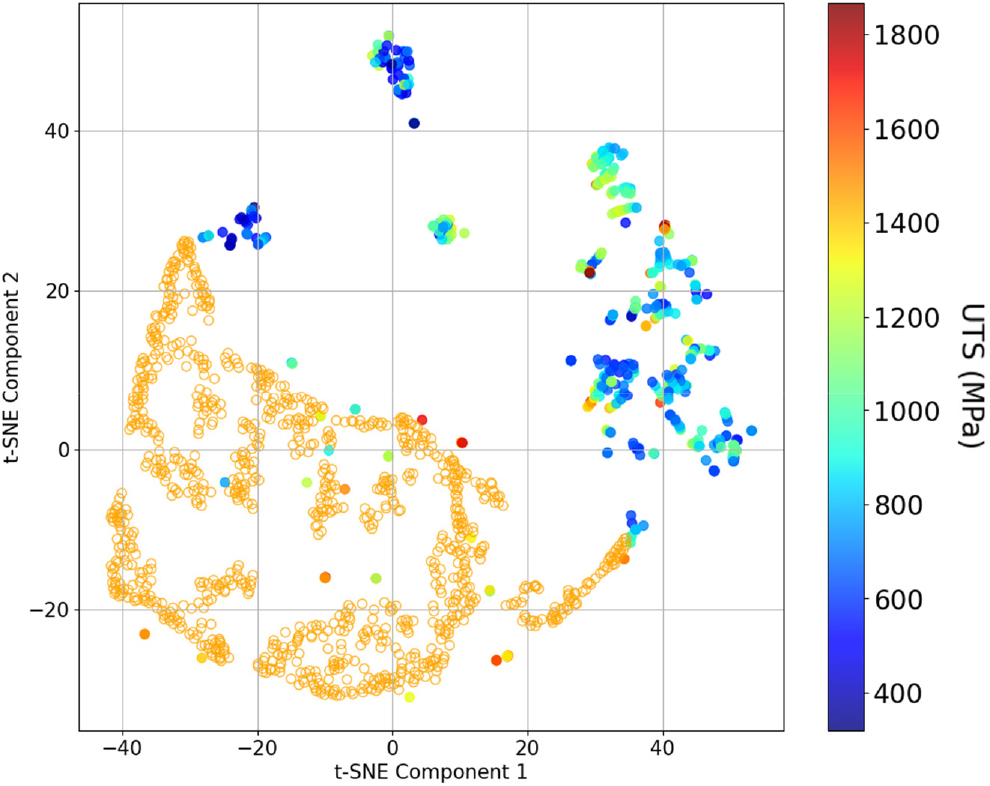
Fig. 11은 501개의 학습 데이터셋과 VAE를 통해 생성된 데이터들의 공간 분포가 차원 축소 기법인 t-SNE를 이용해 시각화한 것이다. 여기서 데이터셋의 원래 조성과, 생성된 데이터는 구분하여 나타내었다. 생성된 데이터의 분포는 1,400 MPa 이상의 높은 최대 인장 강도를 가지는 데이터의 분포에 넓게 분포하고 있음을 확인할 수 있다. 이는 생성된 데이터가 높은 최대 인장 강도를 보이는 데이터와 유사함을 보여준다.
4. 결 론
본 연구에서는 VAE 잠재 공간의 고강도 영역을 목표로 하여 생성한 1,000개 신규 데이터의 예상 UTS는 약 800~1,600 MPa 범위에 분포하는 것을 확인하였으며, 그 결과 모델이 고강도 데이터의 확률분포를 효과적으로 학습했음을 보여준다. SHAP 해석 결과 냉간 압연율 증가는 강도 향상에, 열처리 온도 증가는 강도 저하에 기여하는 경향이 확인되었고, 평균 조성 비율은 낮지만 Al, Co, Mo가 모델 예측에 있어 높은 중요도를 보였다. t-SNE를 통한 차원 축소에서 생성 조성들은 학습 데이터의 고강도 영역을 확장하는 분포를 보여 신규 고강도 HEA 후보 발굴 가능성을 뒷받침한다. 따라서 제안한 프레임워크는 고성능 HEA 후보를 효과적으로 설계할 수 있는 잠재력이 있음을 확인하였다.
