

1. 서 론
재료공학 연구 중에서 소재의 분석을 위해서 사용되는 다양한 방법 가운데 전자현미경을 이용한 이미지 분석 은 여러 목적으로 사용된다. 주사전자현미경(scanning electron microscopy: SEM)을 이용한 소재의 미세구조 분 석, 나노소재의 형상 및 크기 등을 확인하는 데 사용될 수 있다.1,2) 투과전자현미경(transmission electron microscopy: TEM)은 주사전자 현미경과 비교하여 더 높은 전자의 에 너지를 이용하여, 분해능이 높은 특성을 가지며, 고배율 에서 격자의 회절을 통한 구조 특성까지도 확인할 수 있 다.3) 투과 전자 현미경을 이용하여 소재의 분석을 위해 서는 복잡한 전처리 과정을 필요로 하며, 고비용과 장 시간의 분석 시간이 필요하다. 저배율 이미지 촬영에서 는 소재의 넓은 면을 볼 수 있지만 격자(lattice)의 특성 을 확인하기 어려우며, 고배율에서는 좁은 면적에서 격 자의 특성을 볼 수 있지만 높은 에너지를 사용하기 때 문에 소재의 손상이 일어날 수 있고 측정시간이 오래 걸 리는 단점이 있다.3-5)
최근 딥러닝을 이용하여 1 : 1 대응되는 저배율 이미지 와 고배율 이미지 데이터를 통하여 지도학습 기반 초해 상(super resolution: SR) 이미지 구현과 관련된 연구가 많 이 진행되고 있다.6-8) 소재 분석연구에서 주사전자 현미 경 데이터를 이용한 초해상 딥러닝 연구에서 하이드로 겔(hydrogel) 소재 분석에서 소재의 손상을 줄이기 위한 방법으로 저배율 이미지를 고배율로 변환하는 연구가 진 행되었다.6) 광촉매 특성을 분석하되 소재의 손상을 막기 위한 연구에서는 A gC l표면의 Ag 나노입자의 저배율 주 사전자 현미경 이미지를 고배율로 변환하는 연구 또한 딥러닝 기법을 통하여 발표되었다.7) Electron Backscatter Diffraction 분석을 위한 딥러닝 기반 초해상 이미지 분 석과 유한요소해석이 함께 사용되어 소재의 기계적 특 성까지 확인할 수 있는 연구도 소개되었다.8) 이와 유사 한 방법으로 이미지의 노이즈 제거 및 재초점을 위한 딥 러닝 방법이 소재 분석을 위한 주사전자현미경 데이터 를 이용하여 사용되었다.9) 또한, 초해상 생성모델(super resolution generative adversarial network: SRGAN)을 이용하여, 주사전자 현미경과 focused-ion-beam (FIB)를 바탕으로 3D 이미지에 대한 초해상 이미지를 얻은 연 구결과도 있다.10) 하지만, 딥러닝 기반의 투과전자현미경 이미지 데이터를 이용한 초해상 연구는 아직 없으며, segmentation,11) 격자 decoding12)과 관련된 연구내용은 소 개되었다.
본 연구에서는 residual network으로8) 구성된 딥러닝을 이용하여 저해상도(32 × 32 pixels) 이미지(LR)를 초해상 도(super resolution: SR) 이미지(256 × 256 pixels)로 변 환하는 방법을 제시하고자 한다. 나노 소재의 투과전자 현미경 이미지 데이터를 이용하여 딥러닝 기반의 모델 을 학습하여 테스트 데이터에 대하여 적용한 결과를 확 인하였다. 사용된 성능지표(metrics)는 모델을 통해서 얻 어진 초해상 이미지(SR)와 고해상(HR) 원본 이미지와의 픽셀사이의 평균절대오차(mean absolute value: MAE),13) peak signal-to-noise ratio (PSNR),14) structural similarity (SSIM)15)을 사용하여 비교하였다.7) 모델을 통해서 얻어 진 SR 이미지가 참값(HR 이미지)과 유사할수록, MAE 는 작아지는 반면, PSNR과 SSIM은 높은 값을 갖는다. 각 성능지표의 계산방법은 아래의 식 (1) ~ (3)으로 나타 난다.
식 (1)과 (2)에서 N은 이미지 전체의 화소수(number of pixels)를 나타내며, i, j는 이미지의 화소 index를 나 타낸다. 는 딥러닝 모델을 통해서 얻어진 예측값 즉 SR이며 y는 HR에 해당하는 참값이다. 식 (3)에서 l은 휘 도(luminance), c는 대비(contrast), s는 구조(structure)를 나타내며, α, β, γ는 하이퍼 매개변수를 나타낸다. 식 (3) 에서 휘도, 대비, 구조는 각각 식 (4 ~ 6)으로 나타나며, 각 식에서 사용된 μ는 이미지의 평균휘도, σ는 이미지 대비의 표준편차를 의미한다. 딥러닝 모델을 통해서 SR 이미지를 얻은 결과 데이터 수가 많을수록 좋은 성능을 보였으며, 고배율 SR 이미지에서 격자의 특성도 함께 잘 복원되었다. ‘MAE’와 ‘SSIM’ 비용함수를 함께 사용한 모델에서 최적의 SR 이미지를 얻을 수 있었다.
2. 실험방법
Fig. 1은 데이터를 얻기 위한 방법을 보여주며, 1322 × 1322 화소의 크기를 가지는 TEM 원본 이미지를 보여준 다. TEM 이미지를 얻기 위해서 사용된 소재는 수열합 성 방법으로 합성된 DyVO4 나노 소재를 사용하였다.16) 수열 합성에서는 Dy(NO3)3·xH2O용액과, NH4VO3 용액 을 1 :1 비율로 혼합하여 NaOH를 이용하여 pH = 12로 조절하였다. 준비된 용액은 마이크로웨이브 반응기에서 150 °C에서 180분 동안 반응한 후 상온으로 자연냉각 시 켰다. 에탄올을 이용하여 여러 번 세척한 후에 80 °C에 서 건조하여 나노분말을 얻을 수 있었다.16) 사용된 TEM 이미지는 다양한 배율에서 측정되었으며 딥러닝에 입력 되는 이미지는 배율과 관계없이 256 × 256 화소로 분할 된 데이터를 사용하였다. 분할 과정에서 256 × 256 화 소를 가지는 이미지 가운데 나노소재를 포함하지 않는 이미지가 있을 수 있으므로, 이러한 이미지는 딥러닝의 데이터로 사용하지 않았다. 최종 사용된 전체 이미지는 256 × 256 화소수를 가지는 1,169장이며, 학습 데이터(train data)와 테스트 데이터(test data)는 8 : 2 비율로 임의적 으로 나누어서 사용하였다. LR 이미지인 32 × 32 화소 를 가지는 이미지를 얻기 위해서 파이썬 모듈 OpenCV 의 크기조정(resize) 방법을 적용하여 HR 이미지와 1:1 대응되는 LR 데이터를 얻었다.

3. 결과 및 고찰
딥러닝 모델을 이용하여 SR 이미지를 얻는 방법의 효 율성을 확인하기 위해서 우선 파이썬 모듈인 OpenCV 에서 제공되는 고전적인 컴퓨터 비전 방법인 보간법을 확 인하였다. 컴퓨터 비전에서 사용되는 기하학적 이미지 변환(geometric image transformations)17)을 통해서 제 공되는 최근접 보간법(nearest interpolation), 선형 보간 법(linear interpolation), 3차 보간법(cubic interpolation) 의 SR 이미지를 얻은 결과는 Fig. 2와 같다. Fig. 2는 OpenCV 파이썬 모듈에서 제공하는 보간법을 이용하여 32x32 화소(LR) 이미지로부터 256 × 256 화소의 SR 이 미지를 얻은 결과와 함께 HR 이미지도 함께 보여준 다. 다양한 배율의 TEM 이미지의 모두의 경우에 대해 서 3가지 다른 방법의 보간법을 사용한 결과는 Fig. 2 에 나타난다. 각 결과에 따른 성능지표값은 Fig. 3에 나 타나 있으며 TEM 측정 배율의 정도에 따라서 저배율 (low), 중배율(mid), 고배율(high)로 나누어서 비교하였 다. 세가지 보간법의 평균값(mean)은 231장 전체 테스 트 데이터에 대한 결과이며, 고배율, 중배율, 저배율의 대 표적인 1개의 이미지에 대한 결과는 low, mid, high로 표시되어 나타나며, 배율이 높을수록 나노소재의 미세 격 자 정보를 더욱 많이 포함하고 있다.

Fig. 2
SR images were produced from LR images by three different interpolation methods of nearest, linear, and cubic ones, where HR images are shown for comparison.
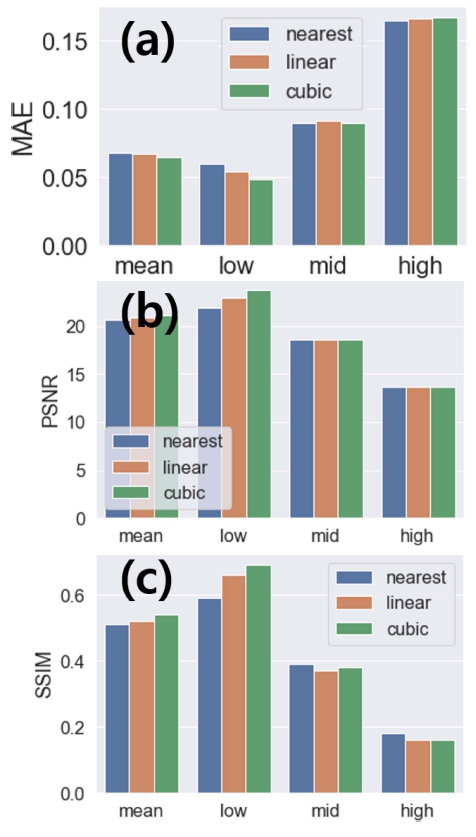
Fig. 3
Metrics of (a) MAE, (b) PSNR, and (c) SSIM for different interpolation methods which are nearest, linear, and cubic interpolation. Mean values indicate average values with 231 test data. ‘Low’, ‘mid’, and ‘high’ correspond to individual representative images in Fig. 2.
Fig. 3에서 평균값 결과를 보면, 최근접 보간법, 선형 보간법, 3차 보간법의 순으로 가장 좋은 결과를 보여주 는 것을 성능지표 MAE, PSNR, SSIM을 통해서 알 수 있다. 하지만, 성능지표는 이미지 화소 간의 값에 대한 수치적 결과만을 보여주기 때문에, 재료과학적 해석이 필 요한 TEM 이미지 분석을 위해서는 이미지의 내용적인 (context) 면을 확인할 필요가 있다. Fig. 3에서 대표적 인 3개의 단일 이미지에 대한 결과를 보면, 배율이 높 아질수록 SR 이미지의 품질이 낮아지는 것을 성능지표 값 변화를 통해서 확인할 수 있다. 저배율에서는 나노 소재의 형태와 모양등이 LR 이미지에 비해서 SR 이미 지에서 어느 정도 뚜렷해지며 3가지 성능지표 모두 평 균값보다 좋은 것을 Fig. 3을 통해서 알 수 있다. 중배 율과 고배율의 경우에는 TEM 이미지에서 격자의 특성 이 나타나는 경우이다. 참값(ground truth)에 해당하는 HR 이미지를 보면 격자의 배열에 따른 구조적 특성을 알 수 있다. 하지만, 중배율과 고배율의 세 가지 보간법 으로 얻은 SR 이미지 결과에서는 격자의 특성이 나타 나지 않는 것을 Fig. 2를 통해서 확인할 수 있다. 그러 므로 중배율과 고배율의 성능지표값은 모두 평균값보다 좋지 않은 것을 Fig. 3을 통해서 알 수 있다.
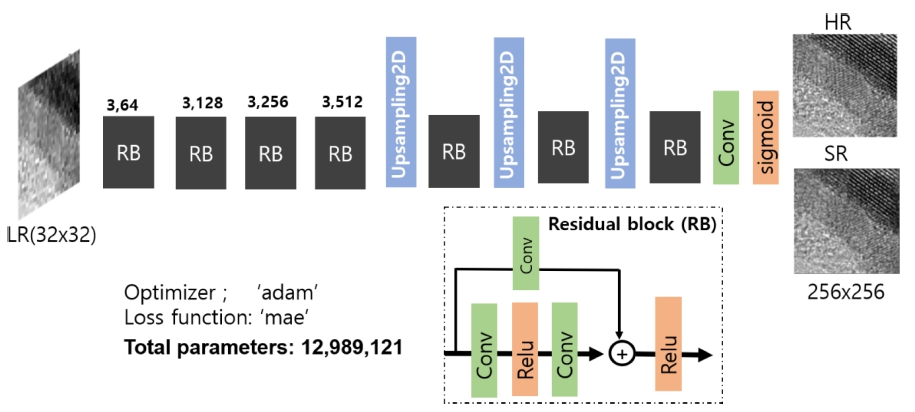
딥러닝을 적용하기 위해서 residual network를 포함하 는 합성곱 신경망 모델의 구조는 Fig. 4와 같다. residual network는 합성곱 신경망의 특성 맵(feature map)을 얻 는 과정에서 공간 정보(spatial information)의 손실을 막 아주는 효과를 가진다.7) 모델 전체 구현을 위해서 반 복되는 기본단위인 residual block (RB)은 Fig. 4에 표 현된 것처럼 합성곱과 활성화 함수 등으로 이루어진다. 합성곱 신경망의 filter size 및 filter 개수는 Fig. 4에 나 타나 있다. 초해상 이미지를 얻기 위해서 ‘Upsampling2D’ 를 3번 진행하면 이미지의 해상도는 32→64→128→256 으로 변환되고, 그 과정에서 특성 맵의 학습이 이루어 지도록 RB를 1개씩 추가하여 모델을 완성하였다. 마지 막 합성곱층은 ‘sigmoid’ 활성화 함수를 통해서 참값과 유사한 화소의 값이 모델의 학습을 통하여 얻어지도록 하였다. 모델 학습과정에서 최적화(optimization)는 ‘adam’ 을 통하여 이루어진다.
딥러닝은 데이터 수에 의존하는 경향을 보이는데,18) 이를 확인하기 위해서 전체 1,169장의 이미지 데이터에서 학 습 데이터의 수를 3가지(336-train, 561-train, 935-train) 로 바꾸어 가면서 학습하여 3개의 모델을 얻었다. 전체 1,169에서 학습 데이터를 제외한 231장 이미지는 테스 트 데이터이며 각 모델의 성능을 확인하는 데 사용하였다.
Fig. 5는 테스트 데이터 중에서 저배율, 중배율, 고배 율 3가지의 대표적인 단일 이미지에 대한 결과이며, 학 습 데이터 수에 따라서 다른 SR결과를 보여준다. 성능 지표인 MAE, PSNR, SSIM은 Table 1과 Fig. 6에 정 리되어 있다. 저배율, 중배율, 고배율 모두의 경우에 학 습 데이터가 많을수록 평균값(mean)의 성능지표는 좋아 지는 것을 Fig. 6을 통해서 알 수 있다. 배율에 따라서 각각의 이미지에서 격자를 포함하는 정도가 다르므로, 대 표적 이미지에 대한 분석을 진행하였으며, 아래와 같다. Fig. 5의 저배율 TEM 이미지에서 사각형 점선으로 이 루어진 부분을 중심으로 보면 학습 데이터에 따른 결과 의 차이를 확인할 수 있으며, 데이터 수가 많을수록 좋 은 성능을 보인다. Fig. 5의 중배율 TEM 이미지의 사 각형 점선으로 이루어진 부분을 중심으로 보면, 336-train 모델 결과인 SR 이미지에서는 격자가 보이지 않고, 561- train 모델의 SR 이미지에서는 부분적인 격자만 나타난 다. 중배율의 935-train 모델의 SR 이미지에서는 격자가 가장 잘 나타나지만, 이미지의 가장 자리에서는 HR이미 지에 비해서 완벽하게 복원되지 않음을 알 수 있다. Fig. 5에서 고배율 TEM 이미지의 사각형 점선으로 이루어진 부분을 중심으로 보면 SR 이미지에서 격자의 복원 효 과가 데이터 수가 많을수록 더욱 뚜렷해지는 것을 알 수 있으므로 HR과 유사한 이미지를 935-train 모델을 통해 서 얻을 수 있었다.
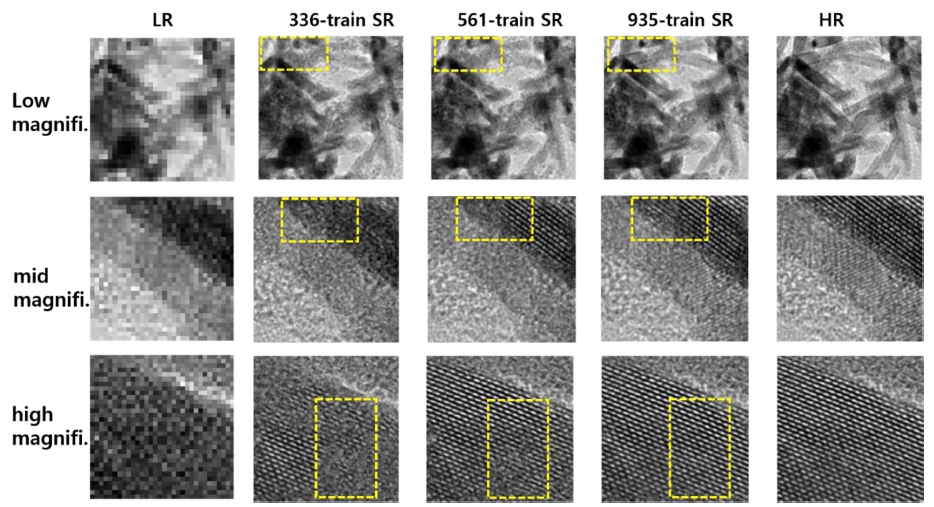
Fig. 5
SR images were produced by the deep learning models with three different numbers of training data for three representative images. Dotted boxes are indicative of the comparison of SR images.
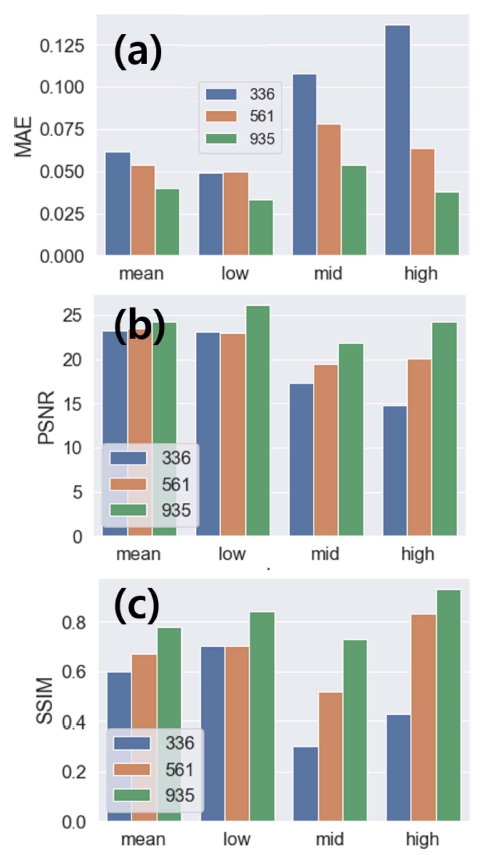
Fig. 6
Metrics of (a) MAE, (b) PSNR, and (c) SSIM for three different deep learning models distinguished by the number of training data which are 336-train, 561-train, and 935-train models. Mean values indicate averaged metrics’ values with 231 test data. ‘Low’, ‘mid’, and ‘high’ correspond to individual representative images in Fig. 5.
Table 1
Metrics of MAE/PSNR/SSIM values for mean values of 231 test data and three individual values corresponding to three representative images of low, mid, and high magnification. Three different interpolation methods, three different numbers of train data, and two different loss functions were independently investigated.
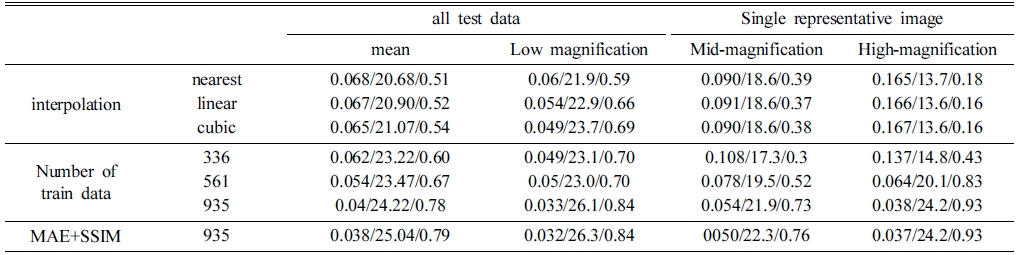 |
Residual network를 포함하는 합성곱 신경망은 공간정 보 손실을 줄이지만, 합성곱 신경망에서 생성되는 filter 의 특성 맵은 국부적(locality)인 특징을 학습한다. 그러 므로 중배율과 고배율의 SR 이미지 가장자리 부분에서 격자의 손실된 부분은 충분한 학습이 이루어지지 않았 다는 것을 의미한다. 격자의 특징을 가장 많이 포함하 는 고배율 이미지의 경우에, 학습 데이터가 많을수록 SR 이미지의 격자의 복원이 전체적으로 향상되는 것을 알 수 있다. 또한, 가장자리 부분에서도 격자의 특성이 어 느 정도 복원되는 것을 알 수 있다. 그 결과 구조적 유 사성을 평가하는 SSIM은 고배율 이미지의 935-train 모 델의 경우, 0.93의 높은값을 나타낸다.
Fig. 7은 학습 데이터 수에 따른 모델의 학습과정에서 1,000 epoch 조건에서 학습 데이터와 20 %로 고정하여 사용된 검증 데이터(validation data)의 비용함수의 변화 를 보여준다. 학습 데이터가 적은 경우는 검증데이터에 대한 비용함수 변화를 보면 epoch에 따라서 큰 변화가 없지만, 학습 데이터가 많아질수록 검증 데이터의 비용 함수가 서서히 감소하는 것을 알 수 있다.19) 즉 HR 이 미지를 얻기 위한 딥러닝 모델의 최적화를 위해서는 데 이터가 수가 많아야 함을 알 수 있으며, epoch에 따른 과대적합은 나타나지 않았다.19)
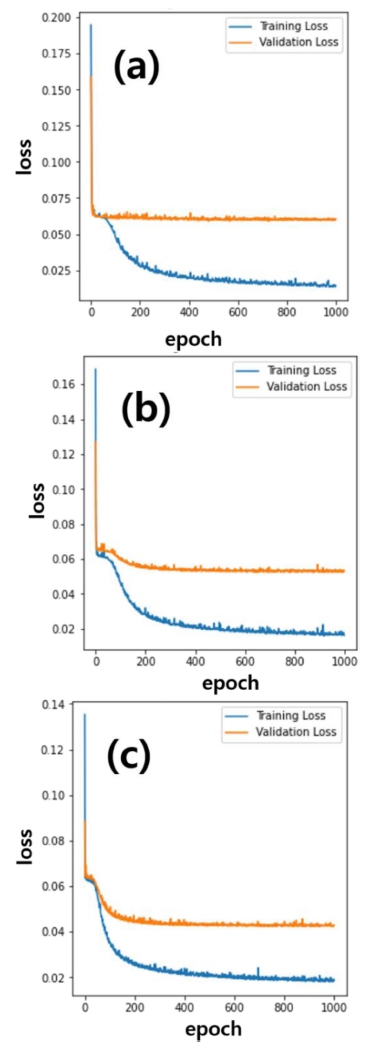
Fig. 7
Loss values on the training and validation data sets in terms of epoch for (a) 336-train, (b) 561-train, and (c) 935-train models.
Fig. 8은 데이터 수가 가장 많은 935-train 학습 데이 터 조건에서, 미세조정을 통하여 최적의 SR이미지를 얻 기 위해서 비용함수(loss function)의 조건을 달리한 결 과를 보여준다. 첫번째 조건은 MAE만을 비용함수로 사 용한 결과이며, 두 번째는 MAE와 SSIM을 1:100의 가 중치를 가지고 학습한 모델의 결과이다. 텐서플로우 플랫 폼 딥러닝의 ‘compile’ 조건에서 비용함수 조건을 설정 할 수 있으며,21) 비용함수는 딥러닝의 ‘back-propagation’ 과정을 통해서 학습 파라미터가 업데이트된다.21) MAE 와 SSIM 비용함수를 동시에 설정하였으며 그 비율은 ‘loss_weights’ 조건에서 1 : 100으로 하여 SSIM 가중치 를 높여서 학습이 되도록 하였다. SR 이미지에서 원형 으로 표시된 부분을 보면 SSIM 비용함수를 추가한 모 델의 결과가 초해상 이미지의 손상이 작음을 알 수 있 다. 935-train 조건의 모델에서 서로 다른 두 비용함수 를 사용한 초해상 이미지에 대한 성능지표 결과는 Table 1에 요약되어 있다.
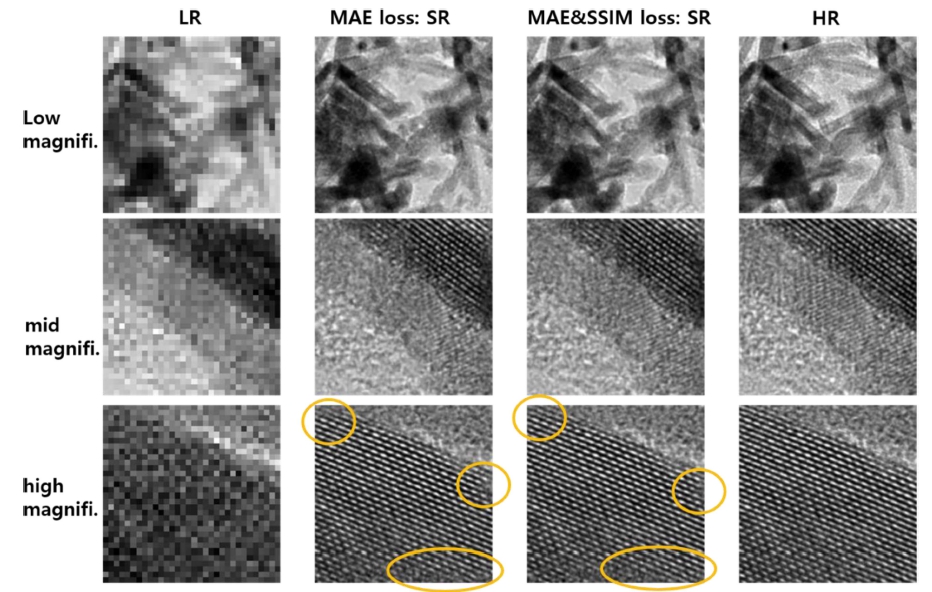
Fig. 8
SR images are produced by the deep learning models with two different loss functions. Only the ‘MAE’ loss function and a combination of ‘MAE’ and ‘SSIM’ loss functions were implemented in the models. Orange circles are guided to compare SR images between two models.
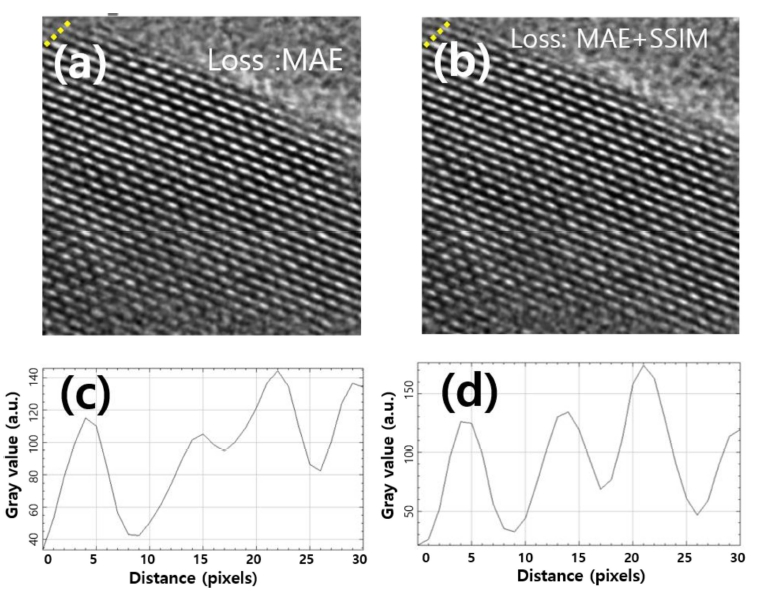
Fig. 9(a, b)는 서로 다른 두 비용함수 조건의 모델에 서 고배율 이미지에 대한 SR 이미지 결과를 보여주며, Fig. 9(c, d)는 초해상 이미지 가장자리 영역의 gray-scale 수치 변화를 image-J 프로그램을20) 이용하여 확인한 결 과이다. SSIM 비용함수는 구조적 유사성 높이는 방향으 로 학습하기 때문에, SR 이미지의 가장자리 부분의 격 자를 더욱 잘 표현하는 것을 Fig. 9(c, d)를 통해서 알 수 있다. 그 결과 SSIM을 비용함수로 포함하는 모델을 이용하여 231개 전체 테스트 데이터의 SR 이미지의 평 균값 MAE/PSNR/SSIM은 각각 0.038, 25.04, 0.79으로 가장 좋은 결과를 보였다.
4. 결 론
나노소재 분석을 위해서 사용되는 TEM 이미지의 SR 이미지를 얻기 위해서 딥러닝을 이용하였다. TEM 이미 지 데이터는 저배율, 중배율, 고배율로 이루어져 있으 며, 저배율은 나노소재의 모양과 형태를 확인할 수 있 으며 중배율과 고배율의 이미지는 격자의 특성을 가진 다. 컴퓨터 비전에서 사용되는 보간법의 결과로 얻은 SR 이미지는 격자의 특성을 복원하지 못하였지만, 최적화된 딥러닝 모델은 격자의 특성을 복원하였다. 딥러닝 모델 은 특성맵을 얻는 합성곱 과정에서 공간정보 손실을 막 기 위해서 residual network를 포함하며 성능지표로는 MAE, PSNR, SSIM을 사용하여 결과를 비교하였다. 학 습 데이터가 많을수록 성능지표가 우수한 결과를 나타 냈으며, SR 이미지의 구조적 유사성이 높은 이미지를 얻 기 위해서 MAE와 SSIM 비용함수를 함께 사용할 때 가 장 좋은 결과를 얻었다.
