

1. 서 론
탄소중립과 관련된 환경 및 에너지 이슈는 인류의 공동문제로서, 산업전반에 많은 변화를 일으키고 있다. 예를 들어, 태양광 에너지 등 신재생에너지 이용 목표를 높이고자 RE100에 참여하는 기업의 수가 증가하고 있으며, 이것은 기후변화에 대응하는 지속가능성 측면에서 해결방안 중의 하나이기도 하다.1) 이와 더불어 화석연료를 줄이기 위한 전기자동차 생산 확대 및 내연기관 자동차의 사용제한 등은 배터리 산업 및 전장부품의 생산확대를 가져오고 있다.2) 결과적으로, 소재 부품 영역에서는 반도체를 이용한 친환경 및 고효율 에너지 소재가 주목을 받고 있다. 폐열을 전기에너지로 변환해주는 반도체 기반 열전소재,3) 태양광 에너지를 전기에너지로 변환해주는 태양전지용 반도체 소재,4) 전기자동차용 고전압과 열환경에 우수한 전력반도체 소재,5) 광촉매 반도체 소재6) 등 산업전반에서 소재 기술분야의 반도체는 핵심영역을 담당하고 있다. 또한, 메모리 분야의 전자부품 소재7) 및 디스플레이용 광소자 반도체,8) 고성능 센서에 필요한 반도체9)는 세계 여러 선진국가에서 집중적으로 연구하는 핵심 소재기술에 해당한다. 반도체 소재의 에너지 밴드갭(energy bandgap)은 소재를 활용하는데 가장 중요한 요소가운데 하나이다. 밴드갭은 실험적으로는 여러 가지 방법으로 측정이 가능하며,10) 최근에는 컴퓨팅 성능의 향상과 더불어 밀도범함수이론(density functional theory)을 통한 반도체 소재의 에너지 밴드갭 계산이 활발히 연구되고 있다.11-13) 예를 들어, the Materials Project에서는 146,323개의 소재에 대해서 결정구조와 함께 밴드갭 정보를 제공하고 있다.11)
실험 결과로 얻어지는 소재의 각종 특성 데이터 뿐 아니라 계산 결과를 통한 소재의 물성 데이터가 많아지면서, Material Genome Initiative (MGI)프로젝트가 미국에서 본격적으로 시작되었고, 소재 설계의 많은 부분이 인공지능을 통하여 가능하게 되었다.14) 인공지능 알고리즘의 발전과 함께 다양한 소재 설계 연구가 진행되고 있는데, 그 중에서 소재의 조성(composition)기반으로 한 설계는 초경질 합금,15) 이산화탄소 환원소재 개발,16) 질소 환원을 위한 촉매 개발,17) 비정질 연자성 물질의 포화자화값 예측을 통한 소재 설계18) 등의 예가 있다. 기계학습을 이용한 에너지 밴드갭 예측으로는 페르보스카이트 소재의 밴드갭 예측,12) 실험데이터로부터 얻은 2,458개 소재 데이터를 이용한 기계학습 기반 밴드갭 예측 성능 확인,10) 소재의 정확한 밴드갭 예측을 위한 적층(stacking) 기계학습 모델을 적용한 예가 있다.13,19) 최신 딥러닝 모델을 적용한 반도체 소재설계의 예로는, 생성모델(generative model)기반 큰 에너지 밴드갭(wide energy bandgap) 소재 설계와,20) 그래프 합성곱 신경망(graph convolutional neural network)을 이용하여 소재의 구조적 특성인자를 바탕으로 한 밴드갭 예측21) 등이 있다.
본 연구에서는 AFLOW에서 제공되는 DFT 계산 방법으로 얻은 21,534개 소재의 에너지 밴드갭 데이터를 이용하여 앙상블 알고리즘기반의 기계학습 모델을 이용하여 밴드갭 예측을 확인하였다.13,22) 조성기반의 특성인자 추출을 위해서 중복되는 조성을 가지는 소재의 경우에는, 성분이 같은 소재의 평균값을 사용하였으며.19) 이를 통해서, 최종 12,039소재의 밴드갭 데이터를 얻었다.13) AFLOW에서 제공하는 밴드갭 데이터는 Heyd-Scuseria-Ernzerhof (HSE)에 기초한 밀도범함수 이론계산, 실험값, 또는 피팅(fitting) 등을 통해서 얻어진 결과이다.13,22) 파이썬 모듈을 이용하여 조성기반 특성인자를 얻고, 앙상블 기계학습 모델인 xgboost (XGB)와 randomforest (RF)를 이용하여 예측성능을 비교하였다. 또한 인공신경망을 이용하여 회귀 예측을 통해서 각 모델의 성능지표를 비교하였다. 두 앙상블 기계학습 모델 가운데 우수한 결과를 보이는 XGB를 이용하여 주요 특성인자를 추출하였으며, 이를 통해서 최종 기계학습 모델을 얻었다. 인공신경망의 경우에는 각 신경망 층의 노드수(number of nodes)를 조절함과 동시에, 피어슨 상관관계계수(Pearson correlation coefficients, PCC)를 이용하여 특성인자수를 조절하여 과대적합을 줄이면서 최적화 조건을 탐색하였다. 마지막으로, 특정한 원소들을 포함하는 소재군으로 나누어 예측성능 및 계산값과 예측값의 차이를 나타내는 오차를 계산하였다. 이 모든 과정은 Fig. 1에서 확인할 수 있다.
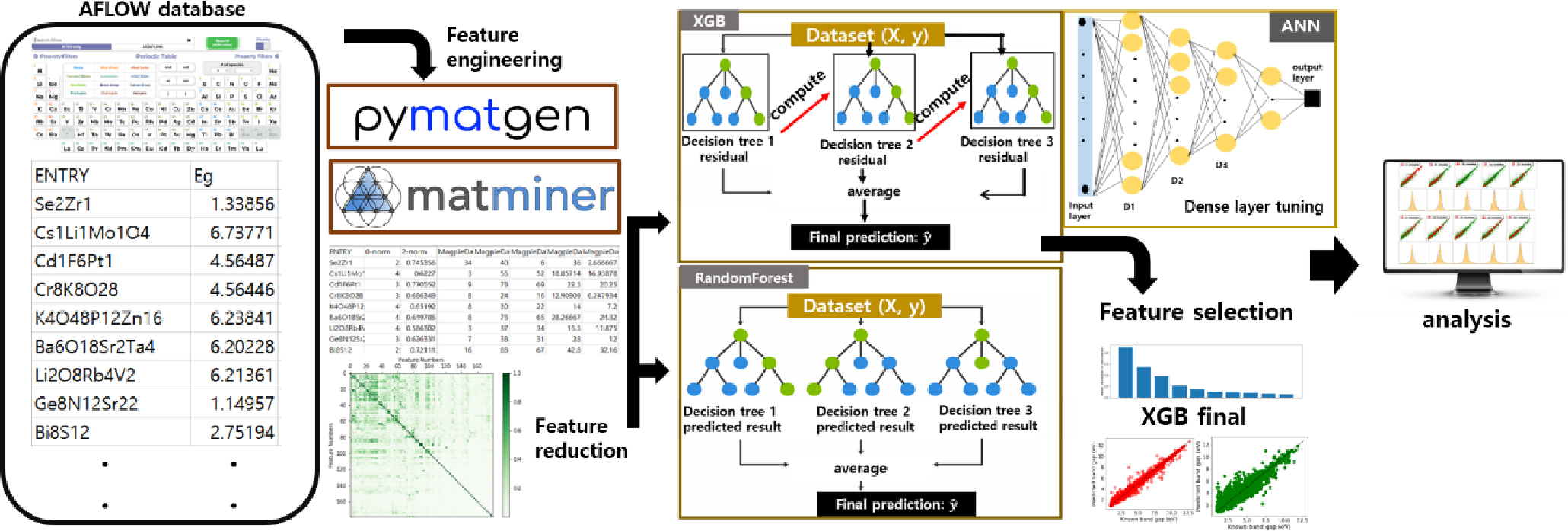
2. 실험 방법
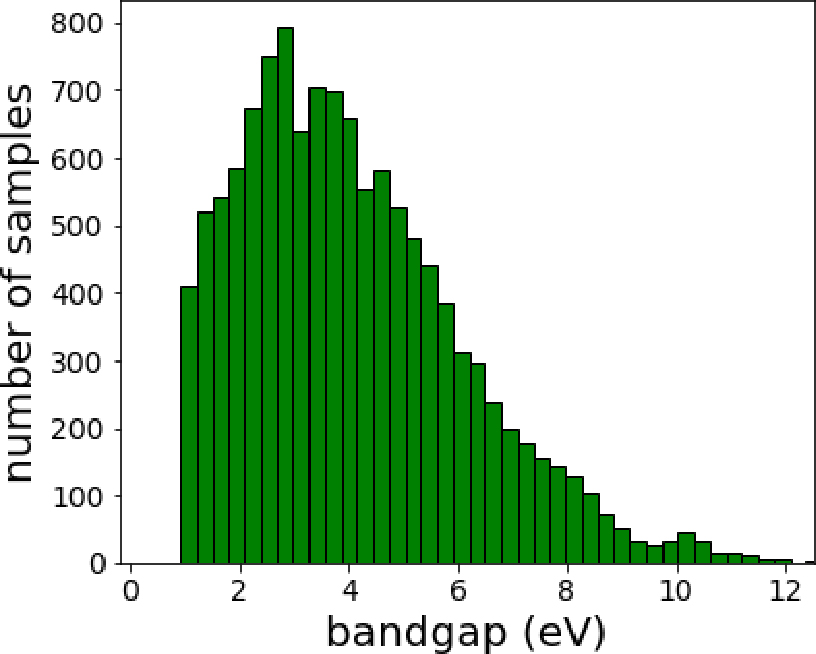
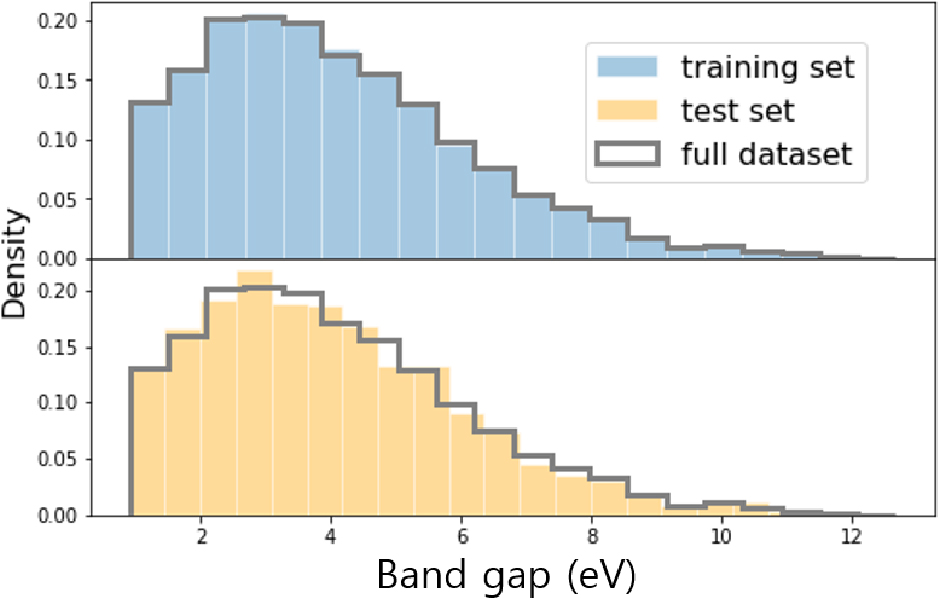
Fig. 2는 사용된 전체 소재의 에너지 밴드갭 데이터의 분포를 보여준다. 가시광선 에너지 대역에 해당하는 1~3 eV에 해당하는 소재가 가장 많이 분포하고 있으며, 부도체에 해당하는 12 eV 밴드갭 에너지를 가지는 소재까지 포함하고 있는 데이터임을 알 수 있다. 기계학습 기반 예측을 위해서, 실험 데이터가 포함되지 않은 경우에는 주로 조성 및 계산으로부터 얻은 소재의 구조특성을 특성인자(feature)로 사용하게 된다. 소재의 구조를 이용한 특성인자는 그래프 합성곱신경망(graph convolutional neural network)에서 많이 사용된다.21) 그러나, 소재의 구조 특성은 비정질 소재에서는 사용할 수 없으며, 결정질 소재에서는 실험 및 계산과정을 통해서 얻을 수 있기 때문에 추가적인 단계가 필요하게 된다. 본 연구에서는 AFLOW에서 제공하는 소재의 조성 정보만으로 에너지 밴드갭을 예측하는 것이 목적이며, 이를 위해서 조성기반 특성인자를 아래와 같은 방법으로 얻었다. 소재의 조성이 AxByCz 형식으로 이루어져 있을 경우 A, B, C는 원소에 해당하며, x, y, z는 화학조성비를 나타낸다. 이미 알려진 원소의 특성(물리, 화학, 열, 전기, 자기, 기계적 특성중의 하나)을 통해서, AxByCz 소재의 특성인자는 다음과 같이 계산된다. A, B, C 각 원소의 임의 특성(P)는 P(A), P(B), P(C)로 나타나며, 조성비에 따른 AxByCz의 특성은 식 (1)과 같다.
또한 각 소재에서 포함하고 있는 원소의 조성비의 정보를 통해서 특성인자를 생성한다.23) 예를 들면, 임의의 소재 데이터에서 사용된 원소가 Fe, Al, Si, Zn일 경우 Fe3Si1은 [0.75,0,0.25,0]이며, Si은 [0,0,1,0]로 부호화될 수 있다. 이와 같은 방법으로 조성에 의한 특성인자를 얻어서 입력데이터로 사용한다. 본 연구에서는 위에서 소개한 방법이 적용된 파이썬 모듈 Pymatgen24)과 Matminer25)를 이용하여 217개의 특성인자를 얻었다. 특성인자가 많을 경우, 지도학습에서는 과대적합(overfitting)이 나타날 수 있다.26) 주어진 데이터에만 집중하는 기계학습 모델은 과대적합으로 인해서 사용된 데이터의 예측성능은 학습 과정에서 좋을 수 있지만, 학습에 사용하지 않은 데이터인 테스트 데이터의 예측성능은 감소할 수 있다. 데이터기반 기계학습의 과대적합을 줄이기 위해서, 특성인자간 상호 관계성이 높은 인자는 다음과 같은 방법으로 제거하였다. 특성인자간 상호 관계성은 피어슨 상관관계 계수(Pearson correlation coefficient, PCC)를 통해서 얻을 수 있으며, PCC 절댓값은 0과 1사이의 값을 갖는다.27) 상관관계성이 높은 특성인자는 과대적합을 일으킬 수 있으므로, PCC 절댓값이 0.95를 초과하는 인자는 제거하여, 최종 179개의 특성인자를 얻었다. Fig. 3(a)는 219개 특성인자간의 상호관계성을 나타내는 그림이며, Fig. 3(b)는 상호관계성이 높은 특성인자를 제거한 후 179개 특성인자의 상호관계성을 컬러맵(color map)으로 보여주는 그림이다.
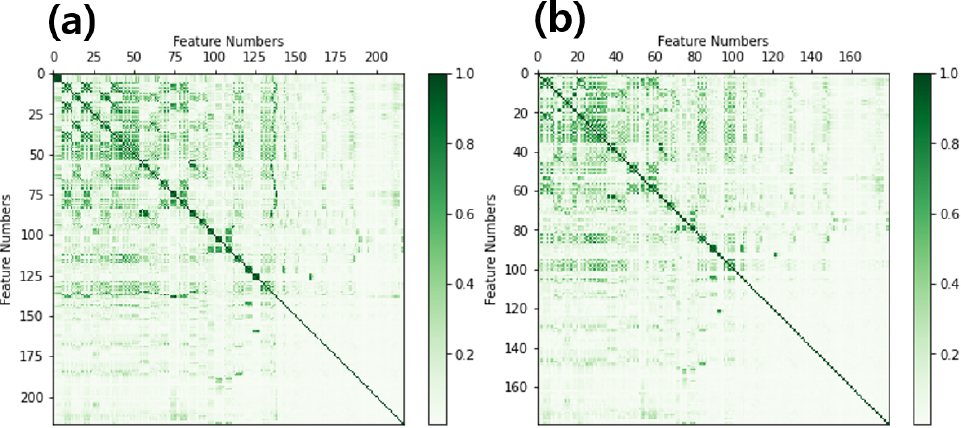
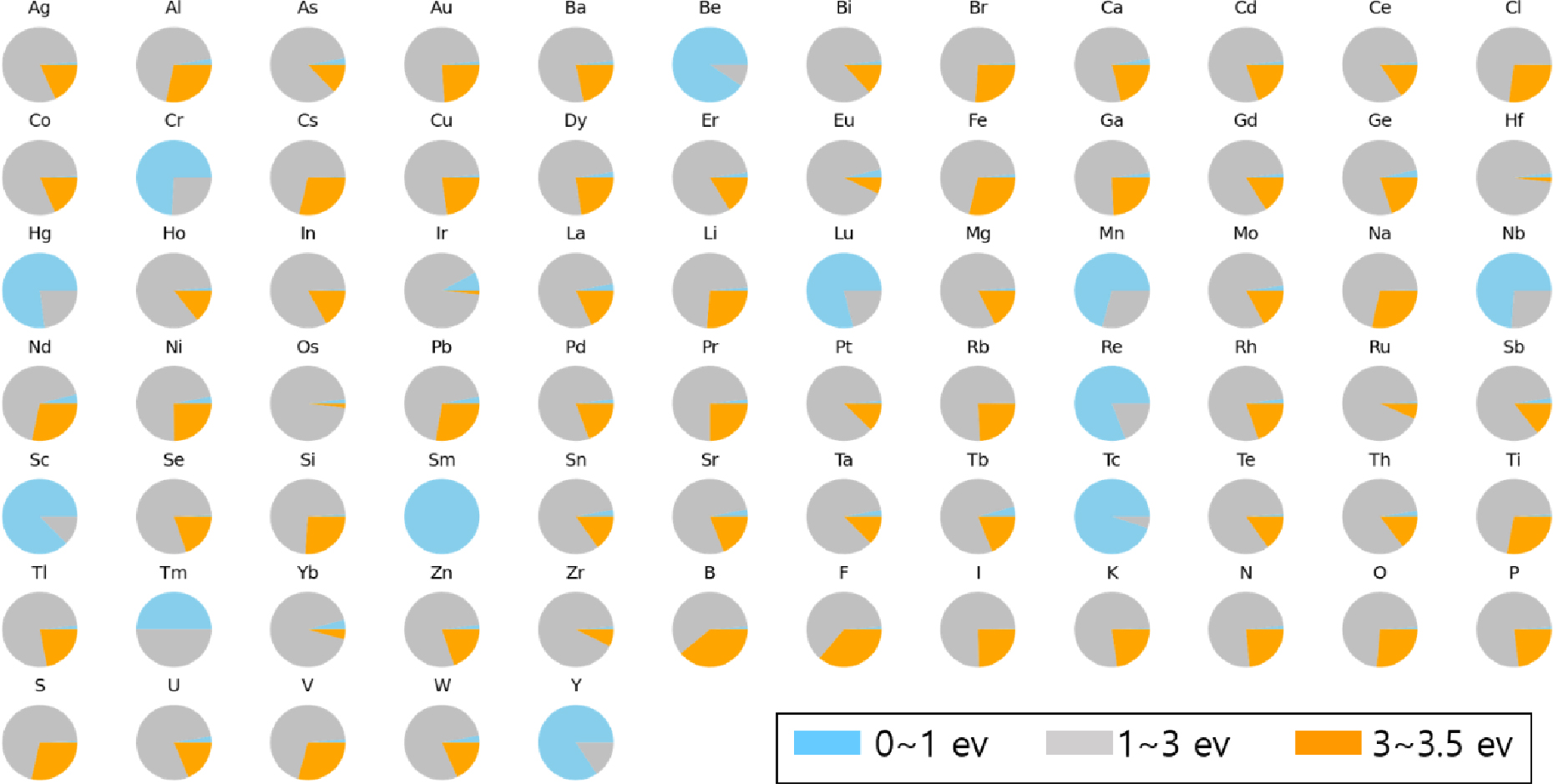
Fig. 4(a)는 바이올린 플롯(violin plot)을 통해서 각 소재의 원소개수에 따른 밴드갭에너지의 분포를 상대적으로 보여준다. 모든 소재는 2개원소부터 6개 원소로 이루어져 있으며, 원소 개수에 따라서 밴드갭에너지 분포가 차이가 나는 것을 알 수 있다. Fig. 4(b)는 전체 데이터세트에 포함되는 소재의 원소개수에 따라서, 특정한 밴드갭에너지 영역에 포함되는 소재 개수를 나타낸다. 밴드갭에너지 영역을 0~1 eV, 1~3 eV, 3~3.5 eV의 세개의 영역으로 나누었다. 0~1 eV 영역은 가시광선 이하의 적외선 영역으로 소수의 소재를 포함하고 있으며, 1~3 eV는 가시광선에 해당하는 영역으로 가장 많은 소재를 포함하고 있다. 최근 전력반도체 수요가 급증하면서 GaN (Eg = 3.44 eV), SiC (Eg = 3.26 eV)의 전력반도체 연구가 활발히 진행되고 있으며, 이에 따른 높은 밴드갭에너지(wide bandgap energy semiconductors) 소재의 관심이 높아지고 있다. 전력 반도체 활용 가능성이 높은 3~3.5 eV에 영역에 해당하는 소재의 개수는 Fig. 4(b)에 확인할 수 있으며, 2~4개의 원소로 이루어진 소재에서 가장 많이 보여진다. Fig. 5는 전체 데이터세트에서 각 원소가 포함된 소재의 밴드갭 에너지 영역을 상대적으로 표시한 것이다. Fig. 5를 보면, 원소-밴드갭에너지 맵핑(elements-bandgap energy mapping)에 대한 직관적 이해가 어려운 것이 분명하며, 데이터기반의 기계학습을 통해서 소재의 성분과 밴드갭 에너지를 이해하는 것이 더욱 효과적인 접근 방법임을 알 수 있다.
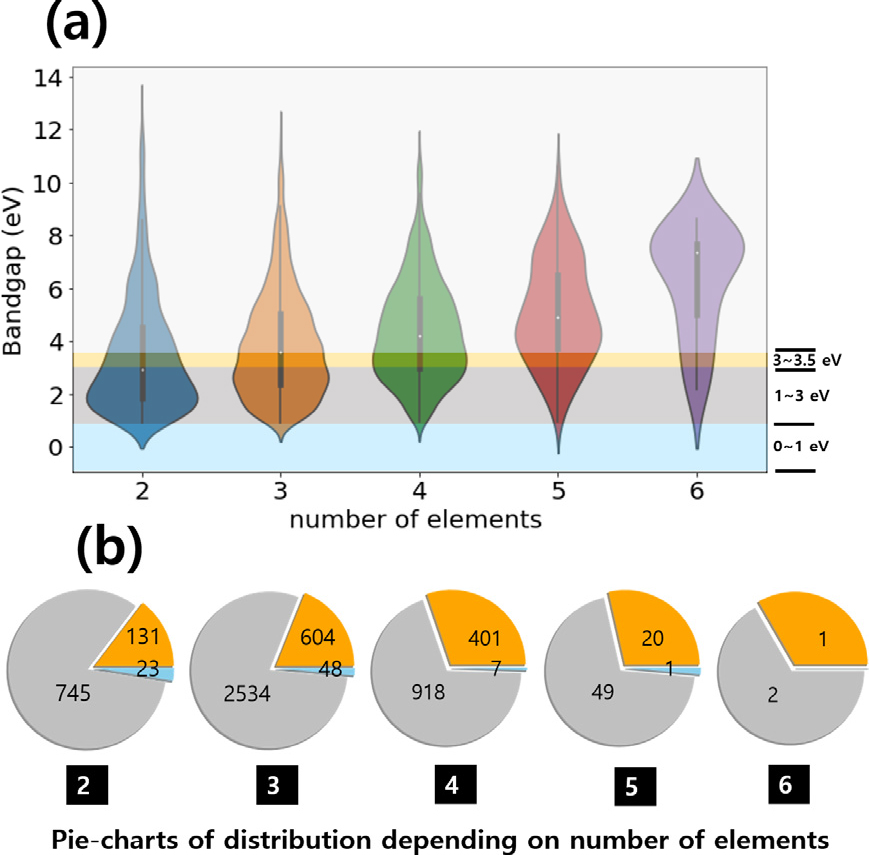
Fig. 4
(a) Violin plot of the bandgaps with respect to the number of elements. The wide sections of the violin plot correspond to regions that contain a higher probability of observations taking a given value. (b) Pie-charts show the distribution of the number of materials depending on the specific band gap grouping (i) 0~1.0 eV, (ii) 1~3 eV and (iii) 3~3.5 eV at each conditions of the number of constituent elements.
지도 학습과정에서 학습데이터와 테스트 데이터는 ‘scikit-learn’에서 제공하는 파이썬 모듈을 이용하여 8:2 비율로 나누어 학습데이터 9,631개, 2,408개의 테스트 데이터를 사용하였다.28)Fig. 6은 전체 데이터와 비교하여, 학습데이터와 테스트 데이터의 밴드갭에너지 분포를 보여주고 있으며, 전체 데이터 분포와 유사한 분포를 가지는 것을 알 수 있다. 이를 통해서 학습과 테스트의 편향성은 고려하지 않아도 되기 때문에, 학습 과정에서 얻어진 모델은 테스트 데이터의 예측에 효과적으로 사용할 수 있음을 보여준다.
3. 결과 및 고찰
Fig. 7은 앙상블 기계학습 모델의 대표적인 RF [Fig. 7(a, b)]와 XGB [Fig. 7(c, d)]모델을 사용한 결과를 보여준다. Fig. 7(a, c)는 학습데이터에 대한 결과이며, Fig. 7(b, d)는 테스트 데이터에 대한 결과이다. 회귀모델의 성능지표로는 결정계수(determination coefficient: R2 score)와 평균제곱오차(root-mean-squared-error, RMSE)를 사용하였으며 아래 식 (2), 식 (3)과 같이 얻어진다. 예측값과 실제값이 일치할수록, R2값은 1에 가까운 값을 가지며, rmse는 0에 가까운 값을 가진다. 식 (2), 식 (3)에서 와 는 i번째 계산값과 예측값을 각각 나타내며 는 n개 데이터의 평균값이다.
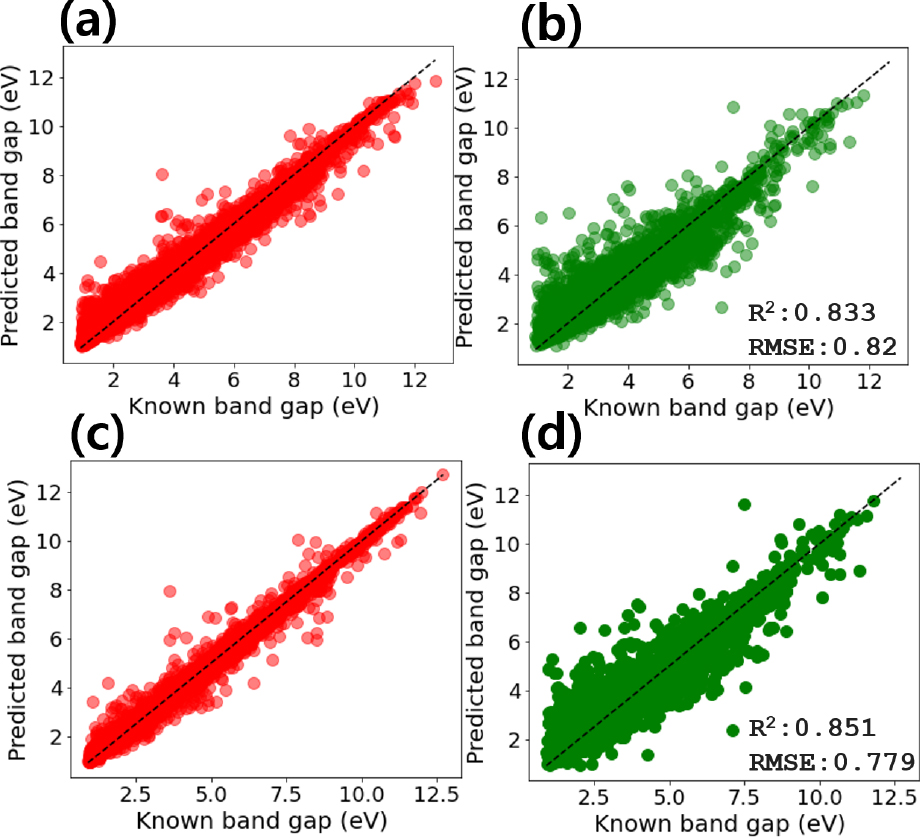
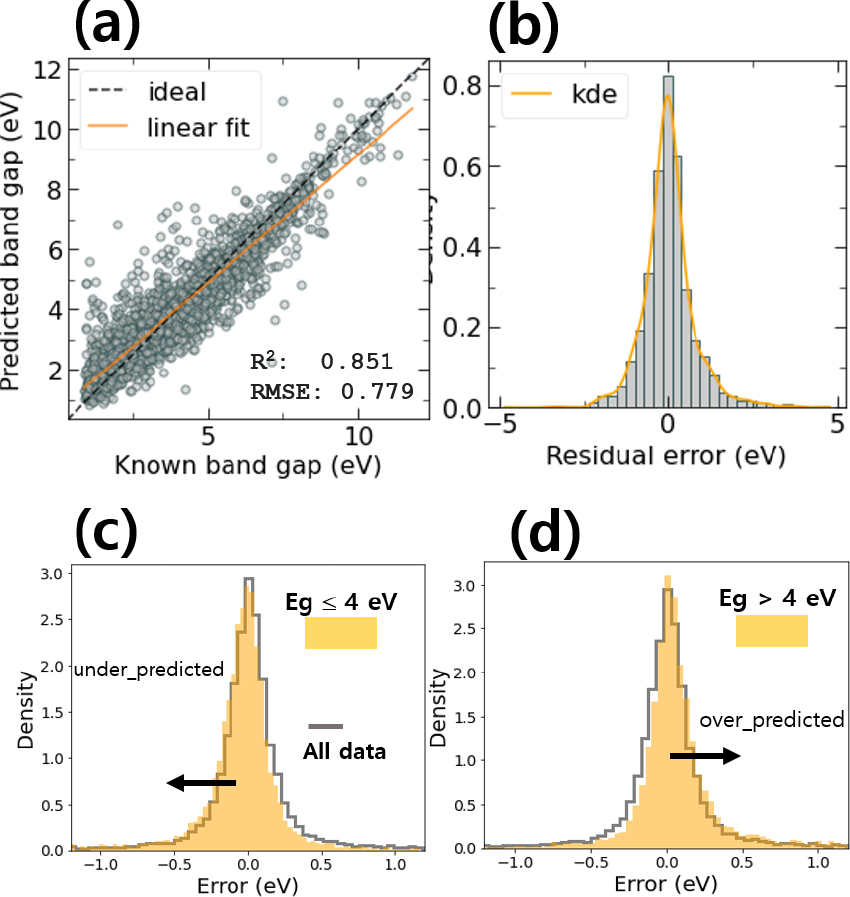
예측성능을 높이기 위해서 교차검증(cross-validation @ cv = 5)을 사용 하였으며, 하이퍼 파라미터 튜닝을 통해서 최적화된 RF와 XGB의 학습된 모델을 이용하여 테스트 데이터에 대한 예측 결과를 얻었다. 에너지 밴드갭 계산값(known bandgap)과 예측값(predicted bandgap)이 일치할수록 Fig. 5의 점선으로 표시된 대각선에 분포하게 되며, 이를 통해서 얻어진 테스트 데이터의 성능지표 R2 score와 RMSE는 Fig. 7(b, d)에 각각 나타나 있다. RF의 R2 score 값은 0.833이며, XGB는 0.851의 R2 score 값을 가지므로, XGB의 모델 예측성능이 우수하다는 것을 알 수 있다. 테스트 데이터의 에너지 밴드갭 계산값과 XGB를 이용한 예측값을 바탕으로 오차(error)를 계산하여 히스토그램(histogram)을 나타내면 Fig. 8(a)와 같다. 오차는 예측값과 계산값의 차이로 계산되므로, 양의 값이면 예측값이 계산값보다 큰 경우이고, 음이면 예측값이 계산값보다 작은 경우를 의미한다. 전체 소재 데이터의 에너지 밴드갭은 1~12 eV의 넓은 범위를 가지므로, 각 영역마다 오차의 부호가 다를 수 있다. Fig. 8(b)는 테스트 데이터의 실제 계산값과 XGB를 이용한 예측값을 비교하여 선형관계성(linear fit)을 실선으로 나타낸 결과와 함께 보여준다. 에너지 밴드갭이 대략 4 eV 이하에서는 예측값이 높게 나타나고, 4 eV 이상에서는 예측값이 작게 나타나는 것을 Fig. 8(b)를 통해서 알 수 있다.29)
두 가지 앙상블 기계학습에서 우수한 예측 성능을 보이는 XGB모델을 이용하여 주요 특성인자를 순차적으로 확인하여 주요 특성인자 수에 따른 예측성능을 아래에서 비교하였다. 179개의 특성인자에 대하여 주요 특성인자 확인법(feature importance)을 적용하여 중요도 높은 순서대로 특성인자를 나열하였으며 이중에서 상위 10개의 특성인자를 확인하면 Fig. 9와 같다.30) 10개의 대표적인 주요 특성인자는 Table 1에도 나타난다. 주요 특성인자를 상위 순위부터 10, 20, 30, 40, 50, 60, 80, 100, 120, 140개로 얻은 후에, 각 특성인자 수에 따른 XGB 학습을 다시 진행하였으며 그 결과로 나타나는 성능지표 변화는 Fig. 10(a)와 같다. 성능지표 R2 score 값과 RMSE 값은 특성인자 10개에서 40개까지 증가할수록 예측성능이 좋아지는 것을 알 수 있다. 특성인자가 60개 이상일 때는 성능지표의 값의 큰 변화가 없으며, 특성인자 120개일 때 가장 좋은 예측성능을 보인다. Fig. 10(b, c)는 특성인자 10개와 60개일 때의, 테스트 데이터에 대한 예측값과 계산값에 대한 결과를 보여준다. 특성인자가 10개에서 60개로 증가할수록 성능지표 R2 score 값이 0.627에서 0.844로 좋아지는 것을 알 수 있다. 소재의 조성비를 통해서 얻은 특성인자를 적절한 수만큼 사용할 때 기계학습 모델에 의한 에너지 밴드갭 예측이 유효하게 작동하고 있다는 것을 Fig. 10을 통해서 확인할 수 있다.
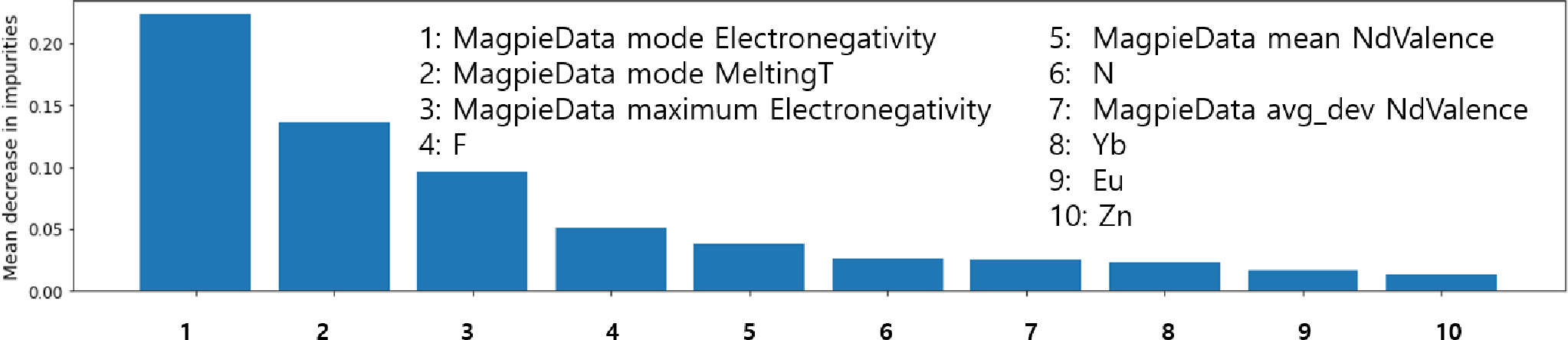
Table 1.
Top 10 features obtained from the feature importance methods with XGB.
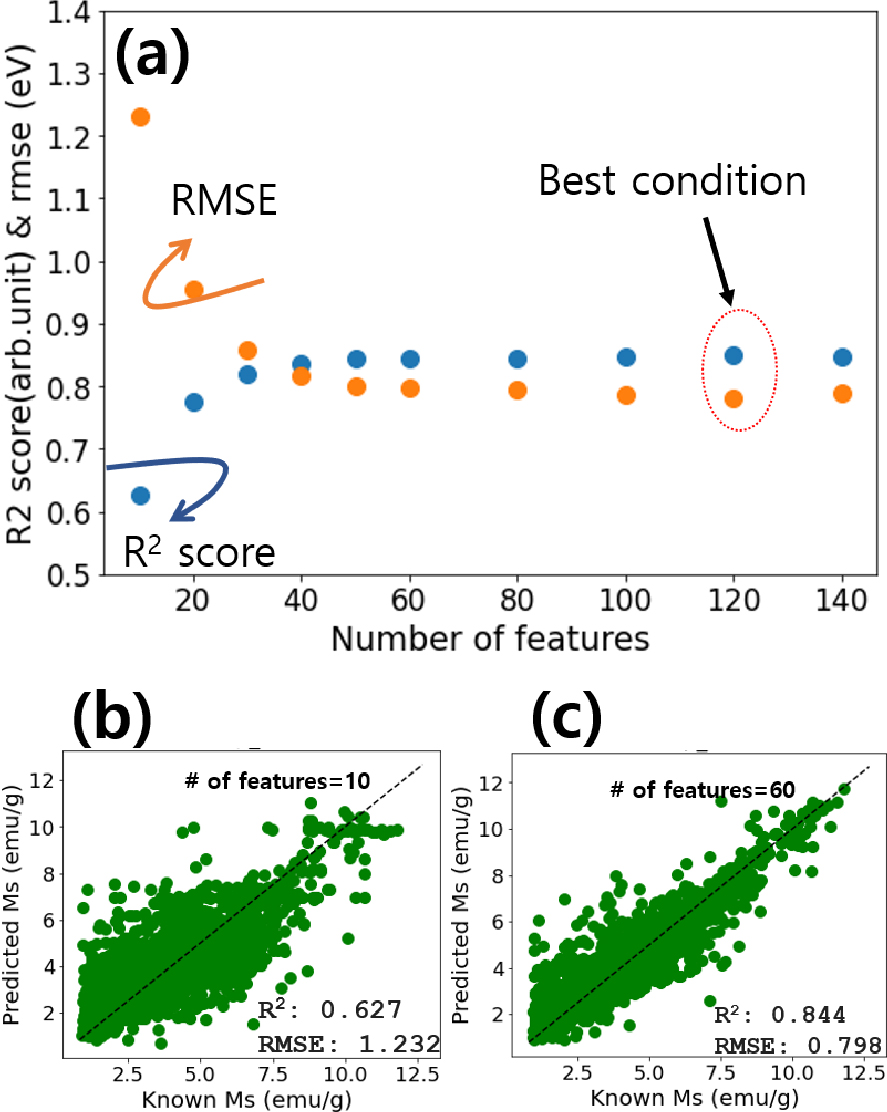
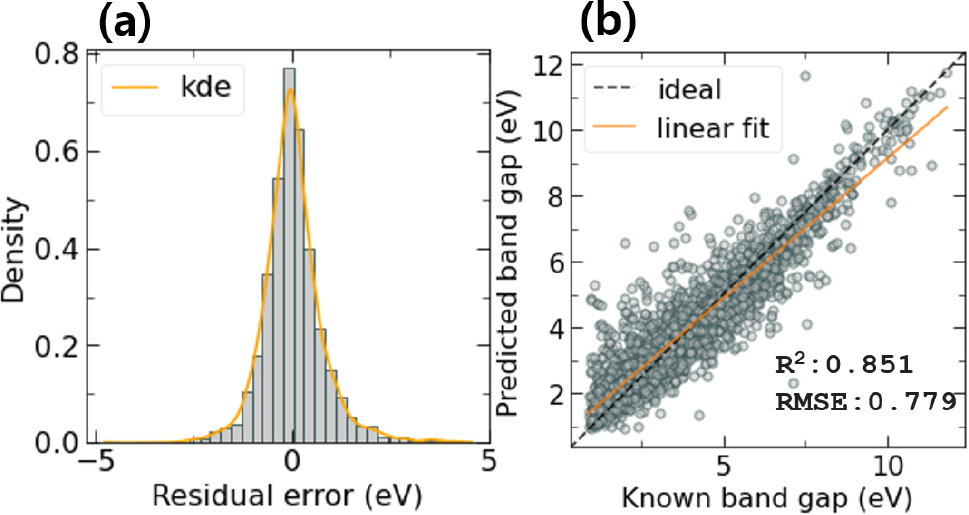
Fig. 11은 주요 특성인자 120개를 바탕으로 XGB를 이용하여 학습한 모델기반 테스트 데이터의 예측 결과를 보여준다. 성능지표 R2 score 값은 0.851이며 RMSE 값은 0.779로서 가장 좋은 결과를 보여준다. 전체 특성인자를 사용했을 때와 마찬가지로, 에너지 밴드갭 4 eV값을 중심으로 과소예측 및 과대예측이 나타나는 것을 Fig. 11(a)를 통해서 알 수 있다. Fig. 11(b)의 오차를 보면 0 eV 중심으로 대칭적인 분포 형태를 보이며, ±1 eV 내에서 90 % 이상의 데이터가 포함되는 것을 알 수 있다. Fig. 11(c, d)는 에너지 밴드갭 4 eV보다 작은 소재와, 4 eV 보다 큰 소재에 대한 오차분포의 히스토그램을 보여준다. 전체 소재 데이터의 오차 분포와 비교하면, 4 eV 이하 소재는 과소 예측, 4 eV 이상 소재는 과대예측으로 나누어지는 것을 Fig. 11(c, d)를 통해서 알 수 있다.
추가적으로 딥러닝 방법을 통해서 예측성능을 확인하기 위해서 인공신경망(artificial neural network, ANN)을 이용하여 지도학습기반 회귀 결과를 분석하였다. Fig. 12(a)는 인공신경망 네트워크를 보여주며, 입력층과 4개의 은닉층(hidden layers: D1, D2, D3, and D4)과 출력층으로 이루어진다. 인공신경망의 과대적합을 줄이기 위해서 Dropout의 비율은 0.2로 고정하였으며, 은닉층 조건은 Table 2를 통해서 확인할 수 있다.
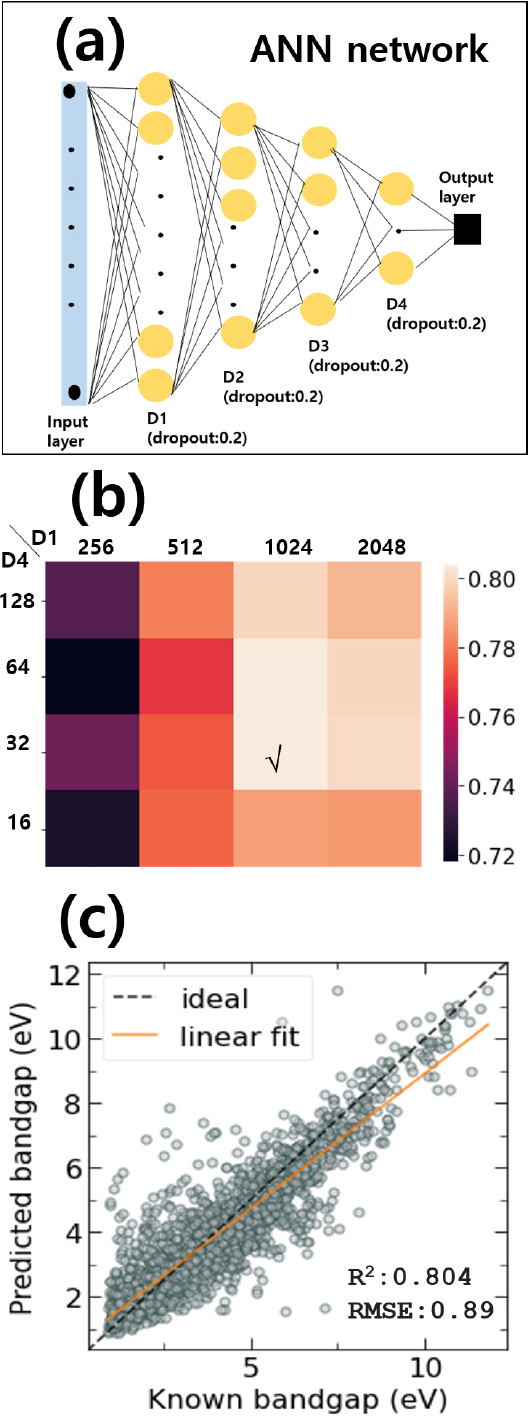
Table 2.
Dense layer conditions to optimize the ANN network. D1, D2, D3, and D4 represent the successive dense and dropout layers, depicted in Fig. 12.
텐서플로우기반의 딥러닝 네트워크를 파이썬을 이용하여 구성하였으며, 학습에 사용한 비용함수는 ‘mean-squared-error (MSE)’를 사용 하였으며, 옵티마이저는 ‘Adam’을 이용하였다. 세부학습조건은 Table 3을 통해서 확인할 수 있다.
Table 3.
Compilation and training conditions used in the ANN network of the present study.
| Compilation | Training |
|
Loss = ‘MSE’ Optimizer = ‘Adam’ Metrics = ‘MSE’ |
Batch size = 256, Epochs = 100 Validation split = 0.2 Call backs = tf.keras.callbacks.ReduceLROnPlateau()* |
Fig. 12(b)는 ANN 네트워크 구성시 은닉층 D1과 D4를 조절해가면서 하이퍼-파라미터 튜닝(hyperparameter tuning)을 통한 성능지표(R2 score)를 비교한 결과이다. D2와 D3는 고정된 조건을 사용하였으며, 특성인자가 입력층을 통과한 첫 번째 D1과 회귀 결과와 연결되는 D4를 조절해가면서 최적 조건을 탐색하였다. Fig. 12(b)에서 보는 것 처럼, D1 = 1,024 nodes, D4 = 32 nodes일 때 가장 우수한 결과를 나타내었으며, 이에 해당하는 테스트 데이터의 예측값과 계산값의 비교는 Fig. 12(c)에서 확인할 수 있다. ANN 모델은 3 eV 이상의 소재에서 과소 예측(underprediction)을 보여주며, 이 때 R2 score = 0.804이며 RMSE = 0.89 eV이다.
특성인자 수에 따른 ANN 모델의 예측성능을 비교하기 위해서 아래와 같은 방법으로 진행하였다. PCC 절댓값이 높은 것은 특성인자 상호간에 관계성이 높다는 것을 의미하므로 과대적합(overfitting)을 낮추기 위해서 PCC 값이 높은 특성인자를 줄일 수 있다. 하지만 딥러닝에서는 작은 수의 특성인자가 사용될수록 예측성능이 감소하므로, 적절한 수의 특성인자를 찾는 것이 필요하다. 본 연구에서는 PCC 절댓값이 각각 0.8, 0.7, 0.6, 0.5 이상인 특성인자를 제거하여, 최종적으로 각각 132, 110, 101, 91개의 특성인자를 얻을 수 있었다. Fig. 13(a-d)는 PCC 값에 따라서 특성인자를 줄여 나갔으며, 그에 따른 남은 특성인자의 각 조건에서(132, 110, 101, 91개) 특성인자 사이의 상관관계를 확인할 수 있다. 각 조건에 따른 ANN 예측성능은 Fig. 13(e-h)에서 각각 확인할 수 있으며, 특성인자 132개를 사용했을 때 가장 우수한 성능을 보여주며, 이 때 R2 score = 0.811이며 RMSE = 0.88 eV이다. 본 연구에서 사용된 RF, XGB, ANN 모델과 더불어 사용된 특성인자 수에 따른 성능지표 결과 비교는 Table 4에 정리되어 있다.
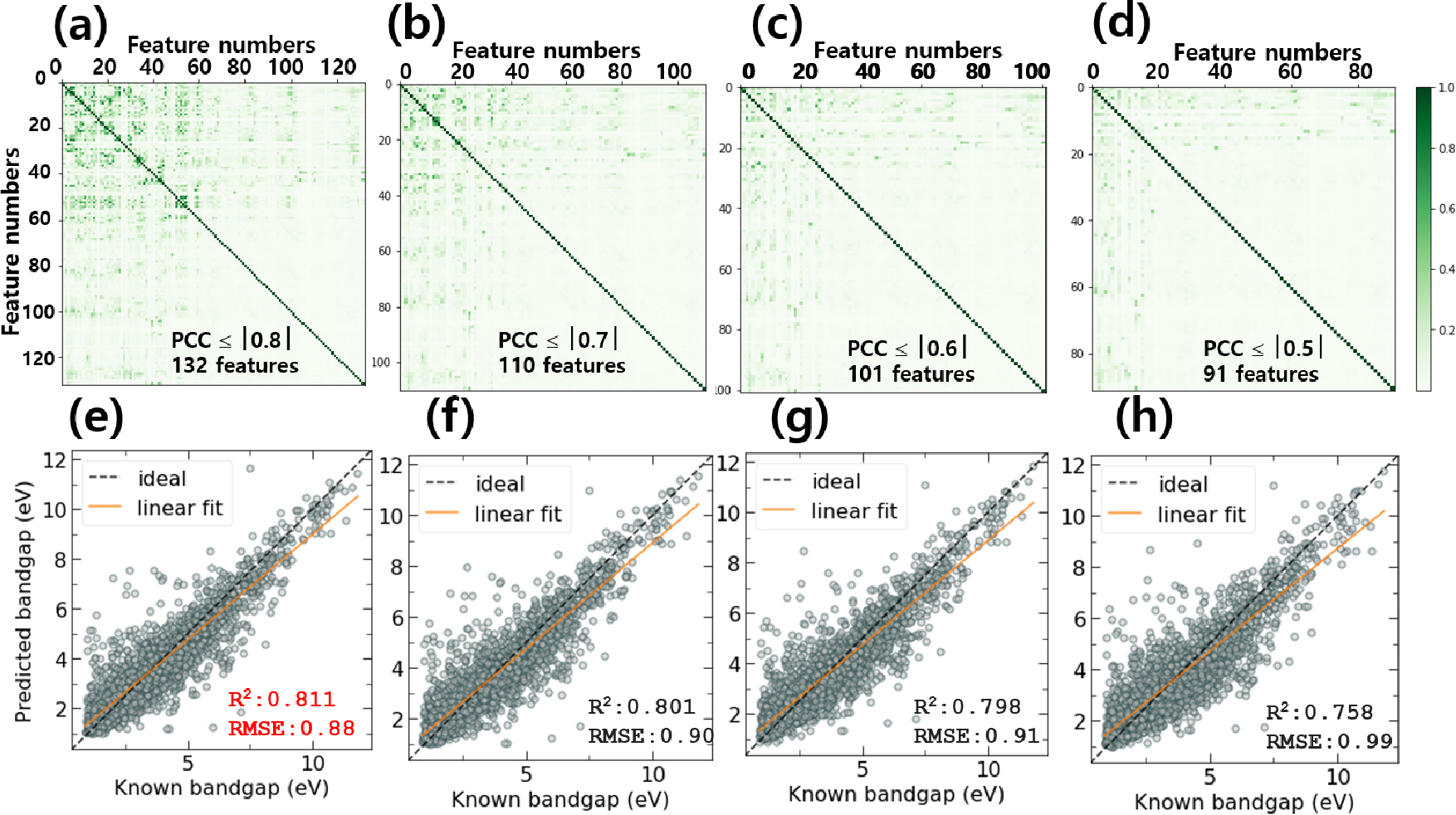
Table 4.
Comparison of R2 scores and RMSE between machine learning models with the different number of features.
| 179 features | 120 features | 132 features | |||
| RF | XGB | ANN | XGB | ANN | |
| R2 score | 0.833 | 0.851 | 0.804 | 0.851 | 0.811 |
| RMSE | 0.82 | 0.78 | 0.89 | 0.78 | 0.88 |
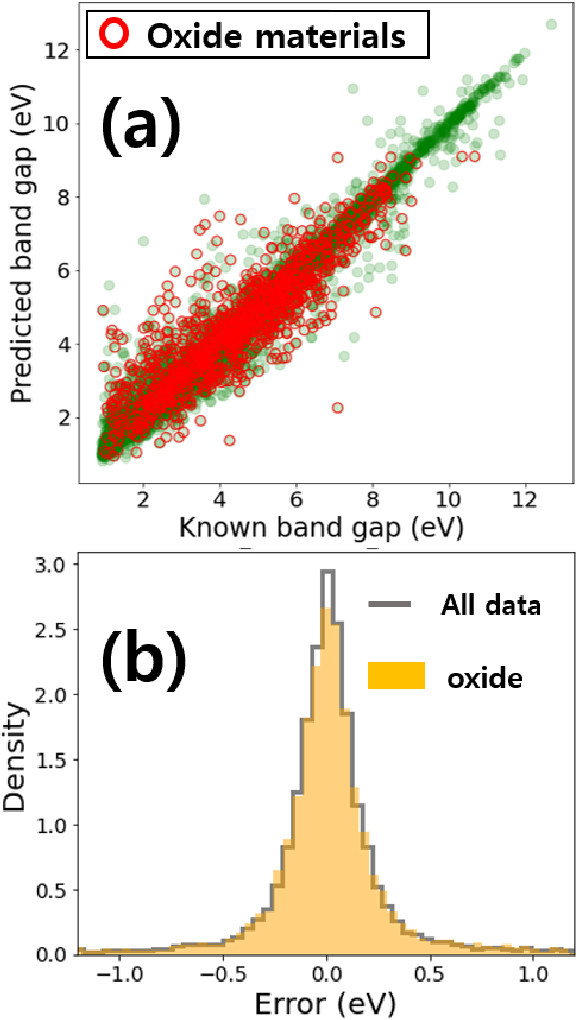
다음으로는, 본 연구에서 사용된 전체 소재 데이터에서 특정한 원소를 포함하는 소재군으로 나누어 에너지 밴드갭 분포, 예측 결과, 오차 분포를 확인하였다. 소재 빅데이터에 대한 통계적 해석 방법은 소재설계에 있어서 중요하게 사용될 수 있으며, 반도체 밴드갭 실험 데이터로부터 얻은 통계적 해석은 최근 Venkatraman et al.에 의해서 소개되었다.19)Fig. 14(a)는 산소를 포함하는 산화물 소재에 대한 밴드갭의 계산값과 예측값의 결과를 보여준다. 산화물 소재는 1~9 eV 사이에 대부분 분포하고 있다는 것 알 수 있다. Fig. 14(b)는 밴드갭 계산값과 실제값의 오차를 표현한 것으로서, 실선으로 표시된 오차분포는 전체 소재(all data)에 대한 것이고, 주황색으로 채워진 오차분포는 산화물 소재(oxide)에 대한 것이다. 전체 소재 데이터와 산화물 소재의 오차분포가 유사하다는 것을 Fig. 14(b)를 통해서 알 수 있다.
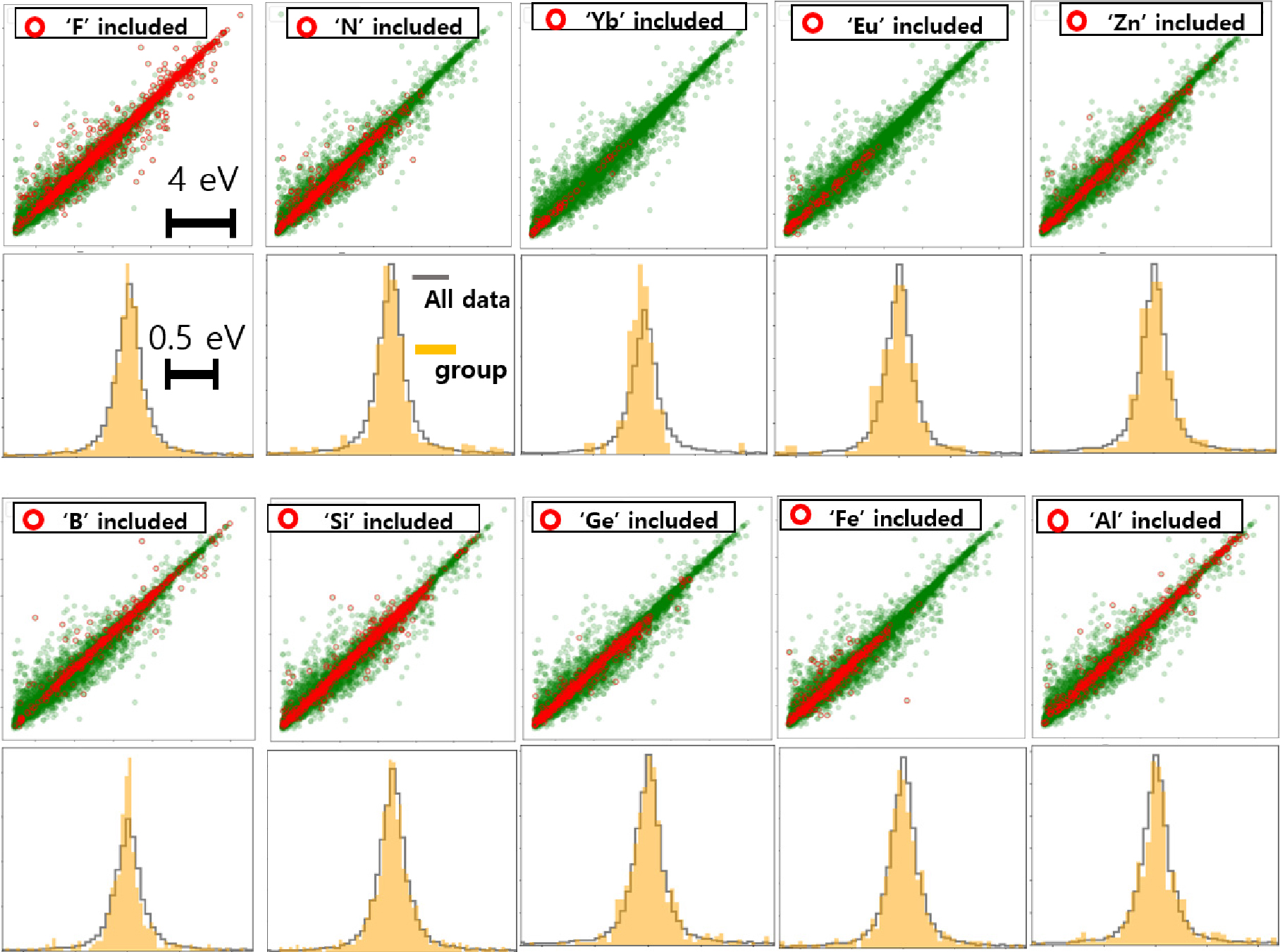
위의 방법과 유사하게, 10개의 원소가 포함된 소재에 대한 예측 결과와 오차에 대한 결과를 Fig. 15에서 확인할 수 있다. Fig. 15의 첫 번째 행과 세 번째 행은 전체 소재와 각 원소가 포함된 소재군의 밴드갭 계산값과 예측값에 대한 선형 회귀 결과를 보여준다. Fig. 15의 두 번째, 네 번째 행은 각 원소가 포함된 소재군의 예측 결과와 계산값에 대한 오차분포를 전체소재의 분포와 비교하여 보여준다.
Fig. 15의 첫 번째 행은 Fig. 9에서 본 것처럼, XGB 모델의 학습과정에서 확인된 주요 특성인자에 포함된 원소 5개(F, N, Yb, Eu, Zn)를 포함하는 소재군에 대한 결과이다. XGB를 구성하는 의사결정트리(decision tree) 알고리즘은 특정원소의 포함 유무에 따라서, 밴드갭 범위를 설정하게 된다. Fig. 15의 첫째 행을 보면, ‘F’을 포함하는 소재는 전체 소재의 범위와 유사하게 넓게 분포하고 있으며, ‘N’을 포함하는 소재는 1~9 eV에 분포하며, ‘Yb’과 ‘Eu’을 포함하는 소재는 1~6 eV에서 이산(discrete) 분포를 가지며, ‘Zn’를 포함하는 소재는 1~10 eV에 분포한다. 가장 좁은 영역의 밴드갭 분포를 가지는 ‘Yb’소재군이 밴드갭 예측에 있어서 오차가 가장 작은 것을 Fig. 15의 둘째 행에서 확인할 수 있다. 즉 ‘Yb’를 포함하는 소재는 특정한 범위의 밴드갭을 예측하기에 좋은 특성인자로 사용될 수 있다는 것을 알 수 있다.
Fig. 15의 세 번째 행의 첫 번째 그림은 ‘B’원소를 포함하는 소재군에 대한 결과이다. ‘B’은 주기율표 5번에 해당하는 작은 크기의 원소로서 다양한 소재에서 침입형 원소(interstitial elements) 또는 화합물로서 많이 사용된다. ‘B’이 포함된 ‘boride’계열 반도체는 오랫동안 비정질 반도체로서 연구되어 왔으며,31) 최근에는 경도가 우수한 큰 에너지 밴드갭을 가지는 소재로 NaB6Si이 소개되었다.32) ‘B’이 포함된 반도체 소재는 넓은 범위의 반도체 에너지갭을 가지며, 계산값과 예측값의 오차는 전체 소재와 비교하면 작은 것을 Fig. 15의 세 번째 행을 통해서 알 수 있다. 다음으로, 대표적인 진성반도체인 ‘Si’과 ‘Ge’을 포함하는 소재군을 비교하였다. Si을 포함하는 소재군이 ‘Ge’소재군보다 더욱 넓은 범위의 에너지 밴드갭을 가지는 것을 알 수 있으며, 계산값과 예측값의 오차는 유사한 것을 알 수 있다. 마지막으로 지구상에 많이 존재하는 대표적인 원소인 ‘Fe’과 ‘Al’을 포함하는 소재군의 경우에,33) 전이금속인 철을 포함하는 반도체 소재는 1~6 eV에 범위에 분포하는 반면, 알루미늄을 포함하는 소재는 전범위에 골고루 분포하고 있는 것을 알 수 있다.
4. 결 론
본 연구에서는 AFLOW에서 제공하는 소재의 밴드갭에너지 데이터를 바탕으로 앙상블 알고리즘의 기계학습을 이용하여 예측성능을 확인하고, XGB가 우수한 예측 성능을 보이는 것을 확인하였다. 사용된 특성인자는 소재의 조성으로 바탕으로 얻었으며, 과대적합을 막기 위해서 상호관계성이 높은 특성인자를 제거하고, 선택적 특성인자를 사용하면서 적절한 특성인자를 찾을 수 있었다. 또한, 인공신경망을 이용하여 밴드갭 에너지를 예측하였으며, 특성인자는 PCC 값을 기준으로 조절하면서 최적의 조건을 찾을 수 있었다. 인공신경망은 빠른 예측성능을 보였으며, 앙상블 알고리즘은 높은 예측 성능을 보여주는 장점을 각각 보여주었다. 전체 소재 데이터에서, 특정 원소가 포함된 소재군에 대한 예측성능을 확인함으로써 소재 데이터의 지속적인 수집이 중요함을 확인하였으며, 소재의 조성 성분만을 통해서 밴드갭 에너지를 예측할 수 있음을 확인하였다.
