

1. 서 론
벌크 금속 유리(bulk metallic glass, BMG) 소재는 인류의 역사와 함께한 금속 소재 중에서도 가장 최근에 발견된 금속 소재에 해당한다.1) BMG 소재는 단결정, 다결정 소재에서는 찾아볼 수 없는 비정질 특성을 가지므로 높은 기계적 강도, 내부식성의 장점으로 인해서 많은 연구가 이루어져 왔다.1) 그 중에서도 Fe기반의 BMG (Fe-BMG)는 철을 포함하고 있기 때문에 자기적 특성을 가지면서 Inoue 박사 및 그 동료들에 의해서 1990년대 중반 소개된 이후로 꾸준히 연구되어져 왔다.1) Fe-BMG는 비정질 특성으로 인해서 보자력이 작고 높은 투자율과 포화자속밀도를 가지면서 우수한 연자성 특성을 가지는 것으로 알려져 있다. 이러한 우수한 연자성 특성으로 인해서 변압기, 센서, 인덕터 등의 소재로의 응용성이 지속적으로 확대되며, 최근에는 미래 모빌리티 관련 소재로서 큰 주목을 받고 있다.1,2) Fe-BMG 소재가 높은 응용성을 갖기 위해서는 유리 성형성(glass-forming-ability)이 우수하여야 하며 이를 위해서는 준금속(metalloids)의 사용이 필수적이다. 하지만 준금속은 연자성에서 요구되는 포화자속밀도를 낮추는 효과로 인해서 적절한 조성원소와 성분비율에 대한 연구가 필요하며, 실험을 통한 시도가 꾸준히 진행되어져 왔다.3)
하지만, 실험을 통한 적절한 조성원소와 성분비율에 대한 탐색은 많은 시간을 요구할 뿐 아니라, 자원 낭비의 결과를 초래하는 반복적인 실험(trial-error methods)은 경제적 소모도 상당하다. 최근 이를 대체하기 위한 방법으로 기계학습을 이용한 소재설계가 많은 주목을 받고 있다.3,4) 기계학습을 이용한 소재 설계에서 사용되는 특성인자는 주로 구조특성(structural features)을 이용한 그래프 합성곱 신경망이 있으며,5) 소재의 성분 특성인자(compositional features)를 이용한 기계학습 또한 많이 연구되어져 왔다.6) 이러한 연구를 바탕으로 기계학습을 이용한 소재 설계는 앞으로도 많은 관심이 집중될 것으로 기대되며, 소재 데이터가 축적될수록 그 중요성이 더욱 증가할 것으로 여겨진다. 최근에 소개된 기계학습 기반의 소재설계 및 예측은 다음과 같다. 초경질 소재 설계,7) 반도체 소재의 밴드갭 예측,8) BMG 소재의 유리 성형 가능성,4) BMG 소재의 열적 안정성 예측,9) Fe-BMG 소재의 연구3) 등이 있다. BMG 소재는 구조특성이 없는 비정질 소재이므로 소재의 성분을 바탕으로 얻을 수 있는 특성인자만으로 기계학습이 가능한 장점이 있으므로 밀도범함수이론(density functional theory) 계산 등을 통해서 추가적으로 특성인자를 얻는 과정이 필요 없는 장점이 있다.6) 또한 실험을 통해서 얻어진 데이터를 사용할 필요가 없기 때문에 새로운 소재의 특성을 예측할 경우, 실험 데이터 없이 예측이 가능하다. 예를 들어 Fe-BMG 소재의 포화자속밀도를 예측하는 기계학습 모델을 구축하기 위해서 supercooled liquid region (ΔTx)를 사용한 경우에는,9) 새로운 소재에 대한 포화자속밀도를 학습된 모델을 통해서 예측하기 위해서 필수적으로 ΔTx를 측정해야 한다.
Fe-BMG 소재가 높은 응용성을 가지기 위해서는 여러가지 특성 중에서도 높은 포화자속밀도(saturation magnetic flux density)를 갖는 것이 중요하다. 규소강(silicon steel)은 2.0 T 정도의 높은 포화자속밀도를 가지고 있다고 보고되고 있으므로, 기존의 규소강등을 대체하기 위해서는 높은 포화자속밀도를 가지는 Fe-BMG 소재 개발이 중요하다. 최근 본 연구그룹에서는 소재의 조성기반 특성인자를 바탕으로 합성곱 신경망(convolutional neural network) 딥러닝을 이용하여 포화자속밀도를 예측하였다.6) 하지만 높은 포화자속밀도를 가지는 소재 데이터가 충분하지 않기 때문에 높은 포화자속밀도를 가지는 소재 설계는 여전히 한계가 있다. 본 연구에서는 Fe-BMG소재의 특성을 예측 하기위해서 소개된 논문3,9)에서 공개된 데이터를 이용하였다. Fe-BMG소재 600개 이상의 데이터를 바탕으로 포화자속밀도를 예측하는 인공신경망(artificial neural network) 기반 회귀모델을 사용하되, 특정 임계값(1.4 T)을 기준으로 예측성능이 우수한 기계학습 모델을 찾기 위해서 F1 score를 성능지표로 사용하여 차별된 연구를 진행하였다. 임계값(1.4 T)은 산업용으로 사용되는 규소강에서 나타나는 포화자속밀도를 기준으로 정하였으며, 타 연구 그룹에서도 유사한 임계값을 사용하여 높은 포화자속밀도를 가지는 연자성 소재에 대한 기계학습 모델을 적용한 연구가 발표되었다.3) F1 score는 정밀도(precision)와 재현율(recall)의 조화평균값에 해당하는 것으로 불균형한 데이터의 분류에서 주로 사용된다. F1 score는 분류 문제에서 참/거짓과 같이 이진(binary) 데이터가 불균형하게 분포할 경우, 정확한 정확도 계산을 위해서 도입되었다.10) F1 score는 아래 식 (1)과 같이 나타낼 수 있다.10)
대부분의 회귀모델은 결정계수(determination coefficient, R2 score) 및 평균제곱근오차(root-mean-squared-error, RMSE)를 사용하여 모델의 성능을 평가하는데 이것은 전체적인 포화자속밀도의 예측성능을 확인할 수는 있지만, 특정 영역에 집중하여 회귀특성을 평가하기는 힘들다.11) 즉, R2 score는 포화자속밀도의 값과 상관없이 주어진 전체 데이터의 예측값과 참값이 얼마나 근접한지를 알려준다. R2 score 및 RMSE는 식 (2), (3)으로 각각 나타낼 수 있다. 예측값과 실험값이 일치할수록, R2 score 값은 1에 가까워지며, RMSE는 0에 가까운 값을 가지게 된다. 아래 식 (2), (3)에서 와 는 소재 데이터의 i번째 실험값과 예측값을 각각 나타내며 는 n개 데이터의 평균값이다.
반면에, F1 score는 임계값을 기준으로 참/거짓 데이터에 대한 성능을 평가할 뿐 아니라 과소 예측(under-prediction) 및 과대 예측(over-prediction)에 대한 비율도 확인할 수 있다. 본 연구에서는 포화자속밀도 1.4 T를 임계값으로 설정하여, 임계값 이상의 높은 포화자속밀도를 가지는 소재 예측에 우수한 모델을 탐색하는 성능지표로 F1 score를 사용하여, R2 score만을 이용하여 탐색한 모델과 그 결과를 비교하였다.
2. 실험방법
Fig. 1은 본 연구에서 사용된 인공신경망 네트워크를 보여준다. 소재의 성분 정보를 바탕으로 획득한 특성인자는 Pymatgen,12) Matminer13) 파이썬 모듈을 통해서 얻었으며, 그 방법은 앞선 연구에서 소개 되었다.6) 각 소재마다 156개의 성분 특성인자(compositional features)와 포화자속밀도를 바탕으로 지도학습으로 이루어지도록 인공신경망 네트워크를 구성한다. 인공신경망 네트워크 구성을 위해서 사용된 노드(nodes) 및 dropout 조건은 Fig. 1에 표시되어 있다. 인공신명망 구축은 텐서플로우(TensorFlow)를 이용하여 파이썬 프로그래밍을 통해서 이루어졌다.
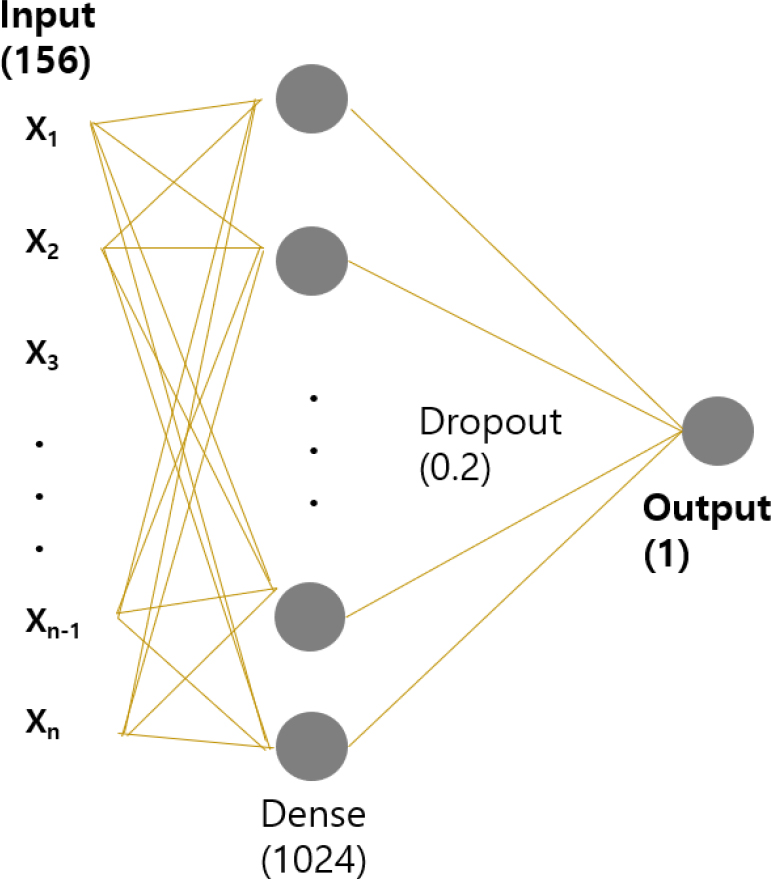
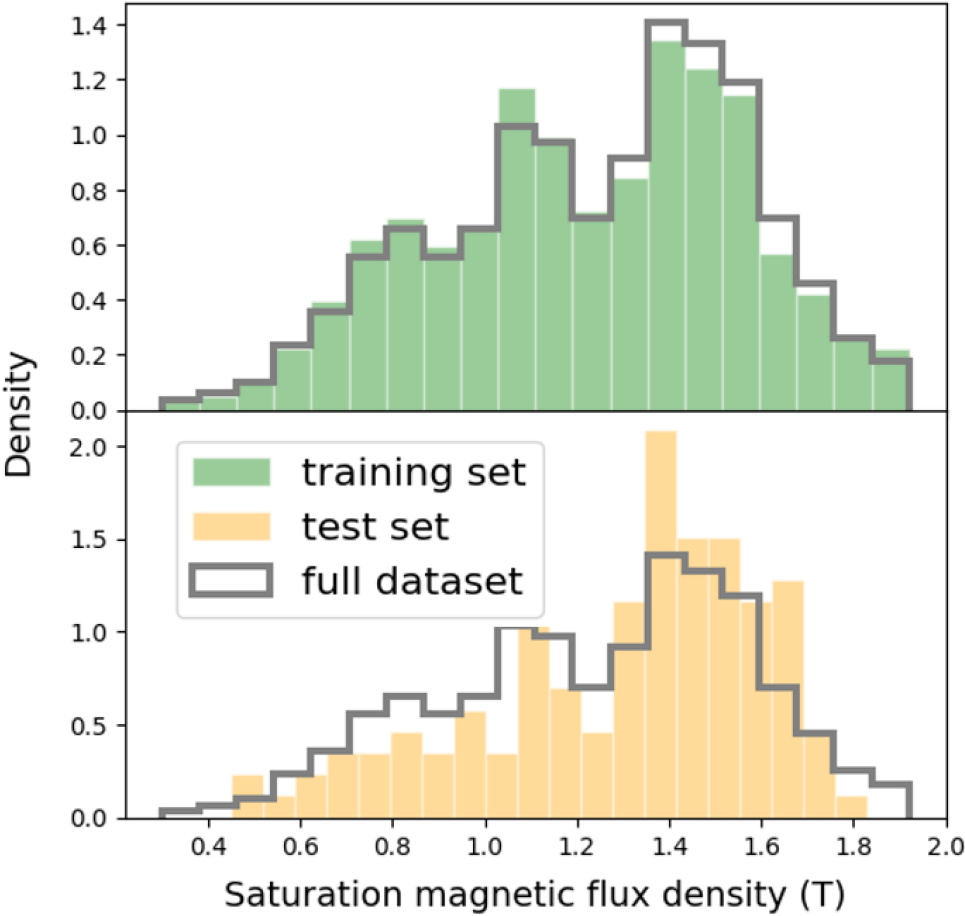
Fig. 2는 기계학습에 사용된 전체 데이터의 포화자속밀도 값에 따른 분포를 보여준다. 소재 데이터의 포화자속밀도는 최소 0.3 T에서 최대 1.92 T 까지 존재하며, 1.4 T 근처의 값에 가장 많은 소재 데이터가 있음을 알 수 있다. 기계학습을 이용한 지도학습 과정에서 학습데이터(training data)와 테스트 데이터(test data)를 8:2 비율로 임의로 나누었으며, 각 데이터의 분포 및 전체 데이터(full dataset) 분포는 Fig. 2,에서 보여준다. 학습데이터와 테스트 데이터가 편향되지 않게 분포하고 있음을 Fig. 2를 통해서 알 수 있으며, 이를 바탕으로 기계학습 모델의 예측성능을 확인하였다.
3. 결과 및 고찰
Fig. 3(a)는 인공신경망을 100번 실행하였을 경우에 나타난 R2 score 및 F1 score 성능지표의 변화를 box-plot으로 표시한 것이다. 인공신경망의 지도 학습 과정에서 학습된 파라미터에 대한 이해는 black-box로 알려져 있는데,14) 이것은 인공신경망의 네트워크에 대한 학습과정을 통해서 얻어진 파라미터에 대한 값이 예측을 잘 수행함에도 불구하고 설명가능한 부분이 많지 않음을 의미한다. 그러므로, 최적의 조건을 탐색하기 위해서 100번의 반복된 학습과정을 진행하였으며, 매 학습과정에서 성능지표를 저장하여 최고 성능을 보이는 결과를 각각 비교하였다. R2 score는 전체 소재데이터에 대한 회귀 예측 결과이므로 100번 실행에서 나타나는 값의 변화가 작은 반면에, F1 score는 임계값을 기준으로 예측이 틀린 경우 변화가 크기 때문에 전체적으로 큰 차이를 보이는 것을 Fig. 3(a)를 통해서 알 수 있다. 포화자속밀도가 큰 값을 가지는 소재에 대한 예측 성능이 우수한 모델을 확인하기 위해서 다음의 2가지 방법으로 학습된 모델을 이용하여 그 결과를 비교하였다. 첫째는, R2 score값이 최대인 모델(R2 best model)과, F1 score값이 최대인 모델(F1 best model)을 각각 이용하여, 학습에 사용하지 않은 테스트 데이터에 대한 예측 결과를 확인하였다. 100번 학습과정에서 매 학습에서 얻어진 성능지표에 대한 결과는 Fig. 3(b)에서 확인할 수 있으며, 회귀 성능을 확인하기 위해서 사용된 2가지 학습 모델은 Fig. 3(b)에 각각 표시되어 있다.
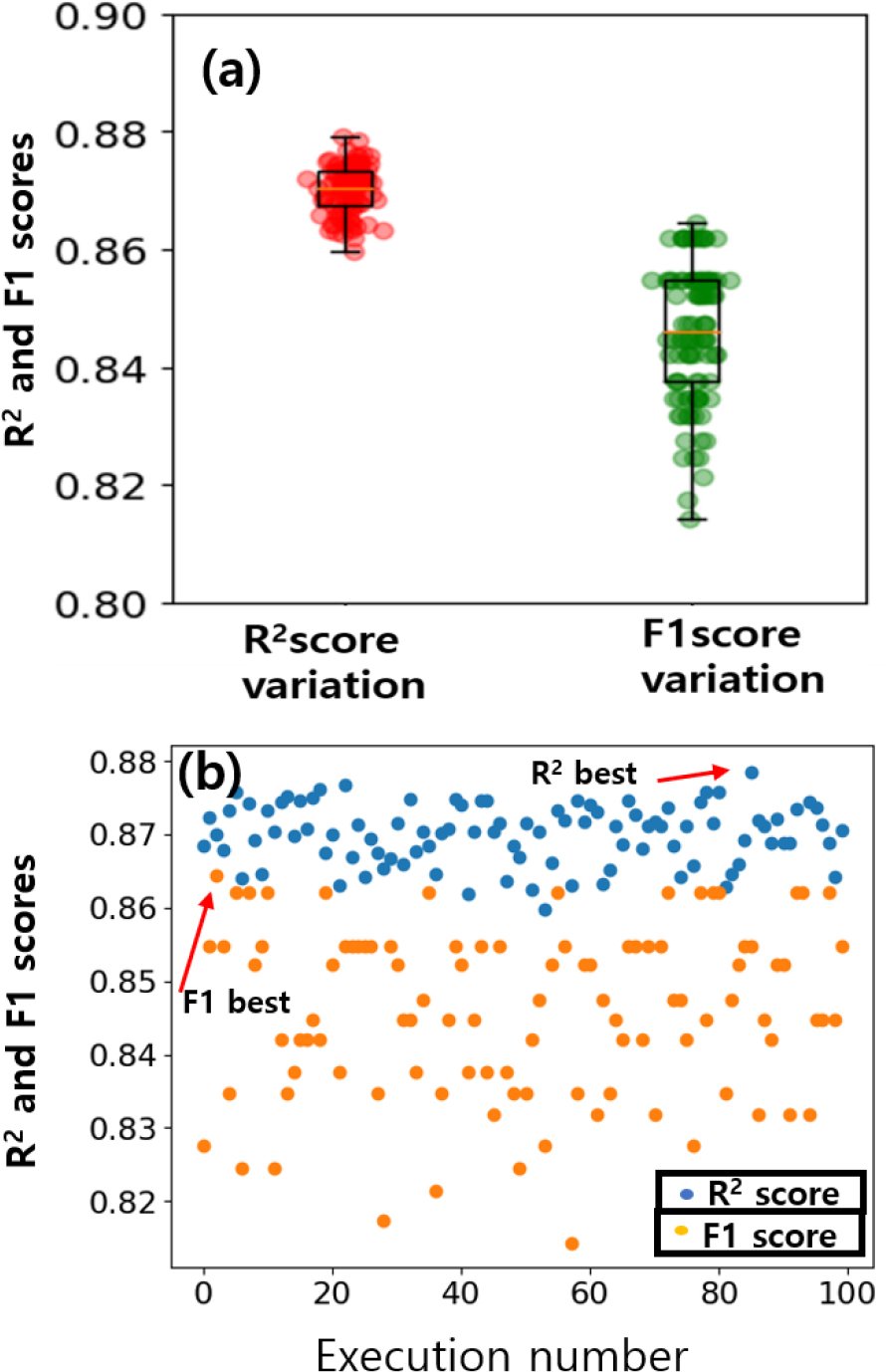
Fig. 4는 테스트 데이터의 포화자속밀도 참값과 인공신경망을 통해서 학습한 모델을 통한 예측값을 비교하여 나타낸 것이다. 전체 622개의 소재 데이터 중에서 20 %에 해당하는 무작위로 추출된 테스트 데이터 125개 데이터에 대한 예측결과를 바탕으로 비교(parity plot)한 것은 Fig. 4(a, b)를 통해서 확인할 수 있다. Fig. 4(a)는 R2 score가 최대인 모델을 바탕으로 예측한 것이고, Fig. 4(b)는 F1 score가 최대인 모델을 바탕으로 예측한 결과이다. 각 모델을 바탕으로 얻어진 성능지표는 Table 1에 요약되어 있다. F1 score가 우수한 모델의 경우 0.864의 F1 score값을 가지며 R2 score와 RMSE는 각각 0.870, 0.111 T이다. 반면에 R2 score가 우수한 모델의 경우에 F1 score는 0.844이며 R2 score와 RMSE는 각각 0.876, 0.108 T이다. 인공신경망을 이용하여 유사한 데이터를 바탕으로 얻어진 타 그룹의 결과는 R2 score = 0.776으로,9) 본 연구에서 사용한 조성기반의 특성인자를 이용한 예측성능이 우수함을 알 수 있다. Fig. 4(c, d)는 포화자속밀도 실험값에 따른 오차(residual error)를 각 모델에서 얻어진 예측값과 실험값을 뺀 값으로 나타낸 것이다. 그러므로 오차가 양의 값이면 과대예측(over-prediction)으로 예측값이 참값보다 큰 경우이며, 오차가 음의 값이면 과속예측(under-prediction)으로 예측값이 참값보다 작은 경우이다. 임계값 1.4 T이상에서는 과소예측이 다수였으며, 1.4 T이하에서는 과대예측을 보이는 것을 확인할 수 있다. Fig. 4(e, f)는 각 모델의 오차에 대한 히스토그램을 나타낸 것이다. 두 개 모델 모두의 경우, 0을 기준으로 대칭적인 모습을 보여주는 것을 알 수 있다.
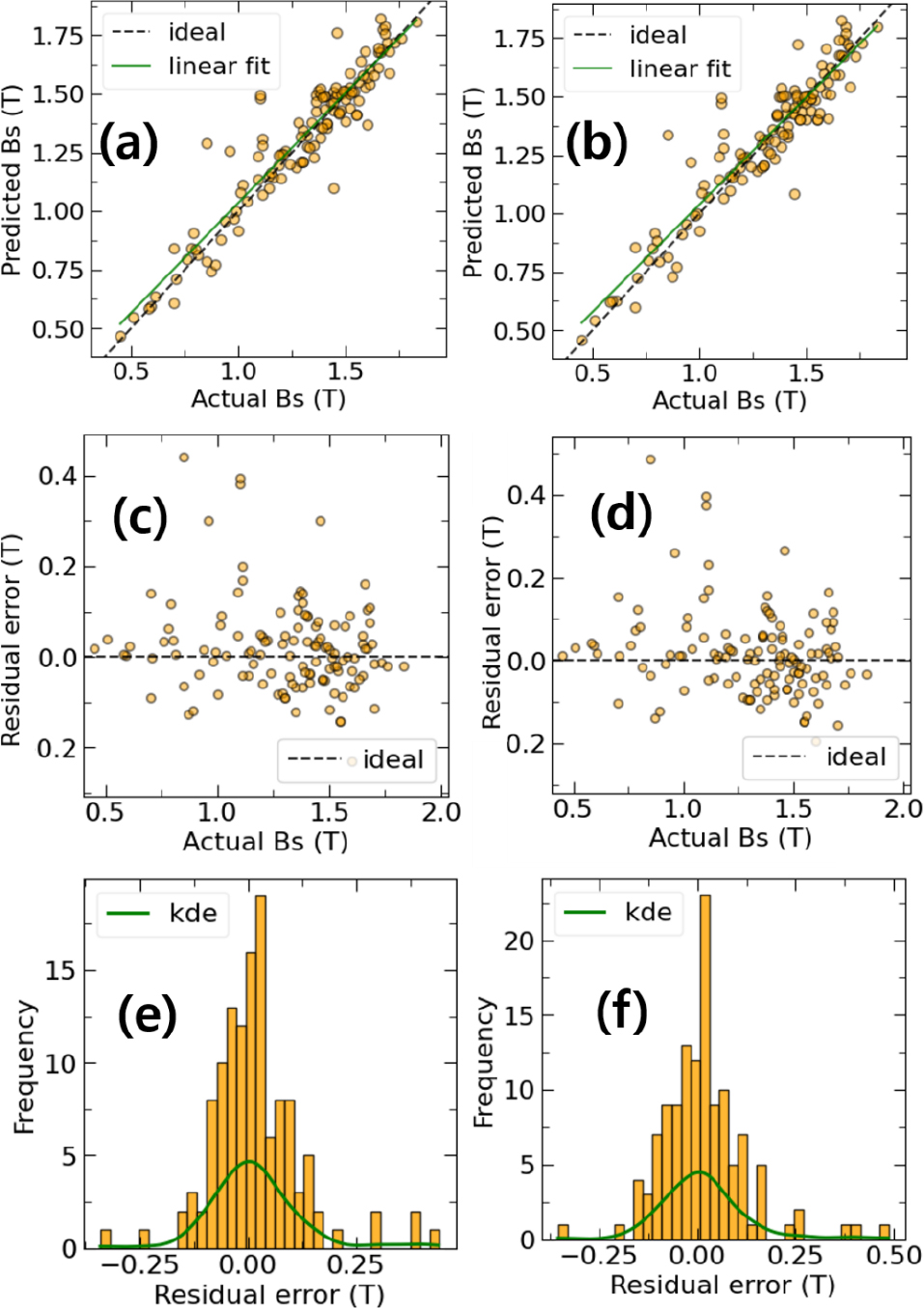
Fig. 4
(a, b) Parity plots between experimental values and predicted values with two ANN models. (c, d) Residual error distribution with two ANN models as a function of experimental Bs. (e, f) Histograms of residual errors were obtained from the difference between the experimental and predicted values.
Table 1.
Predictive performance metrics of two models based on R2 score, F1 score, precision, and recall values.
| R2 score | RMSE (T) | F1 score | Precision | Recall | |
| R2 best model | 0.876 | 0.108 | 0.845 | 0.803 | 0.891 |
| F1 best model | 0.870 | 0.110 | 0.864 | 0.810 | 0.927 |
Fig. 5는 두 모델의 회귀 결과에서 F1 score값의 차이를 이해하기 위하여 임계값 1.4 T를 기준으로 4개 영역으로 나누어서 표현하였다. Fig. 5(a)는 R2 score가 우수한 모델이며, Fig. 5(b)는 F1 score가 우수한 모델을 바탕으로 나타낸 것이다. 임계값 이상을 가지는 소재 데이터의 참값 데이터는 55개로서 임계값 이상의 포화자속밀도에 대한 예측 성공이 높을수록 F1 score는 좋아진다. 두 모델을 비교하여 보면, F1 score값이 우수한 모델의 경우 R2 score값이 우수한 모델보다 좋은 예측 성능을 보이는데, 임계값 이상의 소재 예측에서 2개의 소재에 대해서 더욱 잘 예측하는 것을 알 수 있다. 이로 인하여 F1 score가 큰 차이를 보이는 것을 알 수 있다.
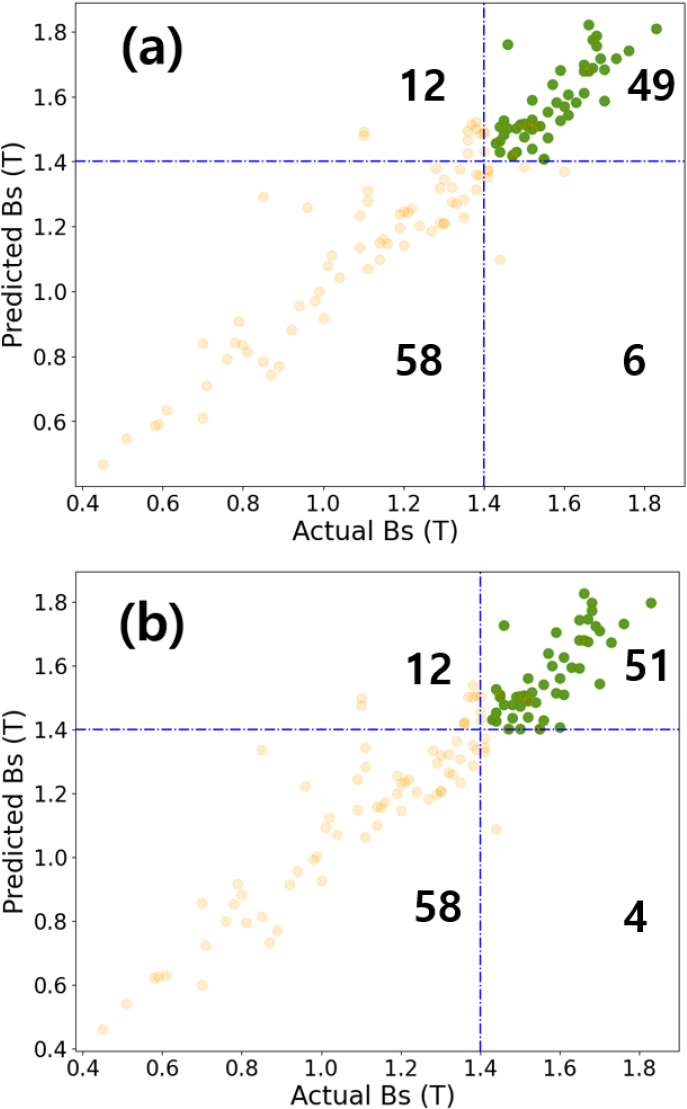
Fig. 6(a)는 본 연구에서 사용된 소재 외에 최근 실험결과를 통해서 소개된 Fe-BMG 소재 중에서 Fe 비율이 높고 포화자속밀도가 높은 27개 소재에 대하여 본 연구에서 사용된 2개 모델을 적용하여 예측 결과를 비교한 것이다.6,15,16) 두 모델(R2 best & F1 best models) 모두 Fe 원소 함량(Fe at%)이 높아질수록 포화자속밀도가 높게 예측되는 것을 확인할 수 있다. 이는 학습에 사용된 소재의 Fe와 포화자속밀도의 관계를 Fig. 6(b)에서 보는 것처럼 비례적인 관계가 있기 때문인 것으로 이해할 수 있다. 또한 학습에 사용된 소재에서는 Fe 85 at% 소재가 없기 때문에, 학습하지 않은 조성 성분에 대한 예측 성능은 낮아진다고 예상할 수 있으며, 그 결과로 Fe 85 at% 소재에 대한 예측 오차가 더욱 큰 것을 알 수 있다. Fig. 6(c)에서 보는 것처럼, F1 score 값이 최고인 모델이 R2 score가 최고인 모델보다 전체적으로 오차가 낮은 것을 알 수 있다. 이것은 임계값 이상의 소재 예측성능이 우수한 F1 score를 기준으로 모델을 선택하였기 때문에 높은 포화자속밀도를 가지는 소재에 대한 예측 성능이 우수하다고 이해할 수 있다.
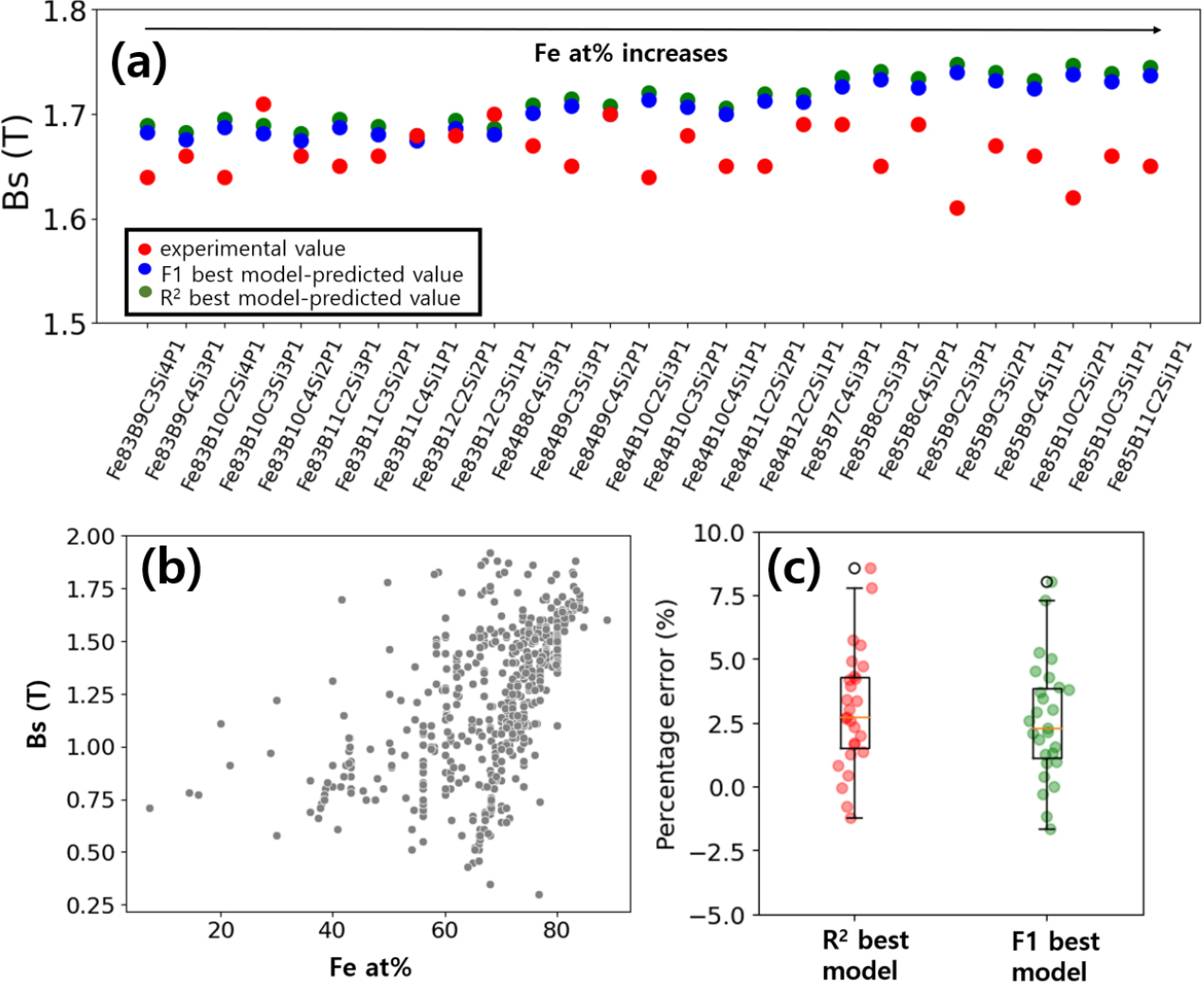
Fig. 6
(a) Comparison between experimental and predicted Bs values with two ANN models for unseen datasets. (b) Scatter plot of experimental Bs values versus Fe at% of full datasets. (c) Box plot shows the distribution of the percentage errors calculated by the experimental and predicted Bs values with two ANN models.
4. 결 론
기계학습을 이용한 소재의 특성을 예측하는 인공신경망 모델의 성능을 이해하기 위해서, Fe 기반의 비정질 합금소재 622개 소재데이터의 포화자속밀도 실험값과, 인공신경망을 이용한 회귀 모델 네트워크를 구성하고, 예측 성능평가를 진행하였다. 회귀 모델에서 주로 사용되는 성능지표인 R2 score에 추가하여 F1 score를 이용하여 모델 성능평가를 확인하였으며 R2 score가 우수한 모델과 F1 score가 우수한 모델을 각각 얻어서 예측결과를 비교하였다. 철을 포함하는 비정질 합금이 연자성 소재로서 응용성이 우수하기 위해서는 높은 포화자속밀도가 필요하다. 본 연구에서는 임계값(1.4 T) 이상의 소재를 잘 예측하는 모델로서 F1 score가 우수한 모델을 통해서 얻을 수 있었으며, 전체 소재의 포화자속밀도를 균형있게 예측하는 모델은 R2 score가 우수한 모델을 바탕으로 얻을 수 있었다. 전체 소재데이터에 포함되지 않은 새로운 소재, 즉 최근에 실험을 통해서 소개된 것으로 높은 포화자속밀도를 가지는 27개 소재에 대하여 본 연구에서 얻은 모델을 이용하여 예측 하였다. 그 결과, F1 score가 우수한 모델이 더욱 좋은 결과를 보이는 것을 확인할 수 있었다.
